Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124

Cardiac surgical procedures, particularly coronary artery bypass grafting (CABG), are the most quantitatively studied therapies in the history of medicine. These studies reveal a complex, multifactorial, and multidimensional interplay among patient characteristics, variability of the heart disease, effect of the disease on the patient, conduct of the procedure, and response of the patient to treatment. Because cardiac surgeons were “data collectors” from the beginning of the subspecialty, it is understandable that efforts to improve the quality of medical care while containing costs found cardiac surgical results (outcomes) an easy target. The dawn of medical report cards made it evident that multiple factors influencing outcome must be taken into account to make fair comparisons of outcomes (see “ Risk Stratification ” and “ Risk Adjustment ” in Section VI ). This scrutiny of results, often by the media, reveals that variability in performing technical details of operations, coupled with environmental factors often not under direct control of cardiac surgeons, contribute to differences in results.
Propensity toward data collection in cardiac surgery was reinforced in the 1970s and early 1980s by challenges from cardiologists to demonstrate not simply symptomatic improvement from operative procedures, but improved survival and long-term quality of life (appropriateness). This resulted in one of the first large-scale, government-funded registries and an in-depth research database ( Box 6-1 ) of patients with ischemic heart disease, as well as a rather small, narrowly focused randomized trial (Coronary Artery Surgery Study ). It stimulated subsequent establishment by the Society of Thoracic Surgeons (STS) of what is now the largest non-governmental registry of cardiac surgical data.
Lauer and Blackstone have reviewed various types and purposes of databases in cardiology and cardiac surgery. Among these are the following, each containing a different fraction of the information on the longitudinal health care of individual patients, and each constructed for differing purposes, although they at times overlap.
A database consisting of only a few core data elements (those likely to be needed for identifying patients according to diagnosis and procedure) on every patient in a defined population.
Typical registries would be all cardiac surgical patients for whom core Society of Thoracic Surgeons (STS) or EuroSCORE variables are collected. The implication is that a registry is an ongoing activity that is broad, but thin in data content. It is enormously expensive to sustain and maintain a registry by manual data entry with in-depth variables. If a “Learning Healthcare System” is to function as envisioned by the Institute of Medicine, detailed clinical data (so-called discrete data) must characterize clinical documentation. Registries and even research databases could then be automatically populated from the electronic health record.
A database consisting of in-depth data about a defined subset of patients. A research database, in contrast to a registry, is narrow and deep. Williams and McCrindle have called such databases “academic databases,” because they usually are constructed by those in academic institutions to facilitate clinical research.
Even with such a database, an individual study may use a fraction of the variables and then must add a number of new variables that are relevant to particular studies. Often the fixed structure of the database is not such that these additional variables can easily be assimilated, so they are often entered into ancillary databases. These ancillary databases may not be available as a resource to subsequent investigators (see Section II ). Data warehouses or, better, semantic data integration are key to making the entire research database accessible.
A database consisting of demographic variables, diagnostic codes, and procedural codes that are available electronically, generally from billing systems. Administrative databases are used by outcomes or health services research professionals for quality assessment.
A database consisting of completely de-identified data, generally of limited scope but usually containing meaningful medical variables, including patient demography, past history, present condition, some laboratory and diagnostic data, procedure, and outcomes. National (and international) databases are intended to be used for general quality assessment; medical health quality improvement; government activities at a regional, national, or international level; and public consumption.
Thus, it is important for all in the subspecialty of cardiac surgery, not just those engaged in bench, translational, or clinical research, to (1) understand how information generated from observations made during patient care is transformed into data suitable for analysis, (2) appreciate at a high level what constitutes appropriate analyses of those data, (3) effectively evaluate inferences drawn from those analyses, and (4) apply new knowledge to better care for individual patients.
It is our desire that the reader realize these goals and not conclude prematurely that this chapter is simply a treatise on biostatistics, outcomes research, epidemiology, biomathematics, or bioinformatics. 1
1 In its narrowest definition, bioinformatics is a collection of methods devised to process genomic data, representing the reality that advances in genomics require sophisticated and often new computer algorithms. Some would say bioinformatics is the next frontier for statistics, others for machine learning. This is the narrow view. The National Institutes of Health (NIH) in the United States has provided a broader view. The NIH Biomedical Information Science and Technology Initiative Consortium agreed on the following definition of bioinformatics , “recognizing that no definition could completely eliminate overlap with other activities or preclude variations in interpretation by different individuals and organizations”: Bioinformatics is research, development, or application of computational tools and approaches for expanding the use of biological, medical, behavioral or health data, including those to acquire, store, organize, archive, analyze, or visualize such data ( http://grants1.nih.gov/grants/bistic/CompuBioDef.pdf ). They go on to define computational biology in a broader context than genomics as “the development and application of data-analytical and theoretical methods, mathematical modeling and computational simulation techniques to the study of biological, behavioral, and social systems.” Thus, to lead from information to new knowledge, they envision bringing together quantitative needs in structural biology, biochemistry, molecular biology, and genomics at the microscopic level, and medical, health services, health economics, and even social systems disciplines at the macroscopic level, with analytic tools from computer science, mathematics, statistics, physics, and other quantitative disciplines. This vision transcends current restrictiveness of traditional biostatistics in analysis of clinical information. This is why we emphasize in this chapter that the material is not simply for surgeons, their clinical research team, and consulting and collaborating biostatisticians, but also for a wider audience of professionals in a variety of quantitative disciplines.
This chapter should be read in whole or in part by (1) all cardiac surgeons, to improve their comprehension of the medical literature and hone their skills in its critical appraisal; (2) young surgeons interested in becoming clinical investigators, who need instruction on how to pursue successful research (see Technique for Successful Clinical Research later in this section); (3) mature surgeon-investigators and other similar medical professionals and their collaborating statisticians, mathematicians, and computer scientists who will benefit from some of the philosophical ideas included in this section, and particularly from the discussion of emerging analytic methods for generating new knowledge; and (4) data managers of larger clinical research groups who need to fully appreciate their pivotal role in successful research (Appendix 6A), particularly as described in Sections I, II, and III of this chapter.
The potential obstacle for all will be language. For the surgeon, the language of statistics, mathematics, and computer science may pose a daunting obstacle of symbols, numbers, and algorithms. For collaborating statisticians, mathematicians, and computer scientists, the Greek and Latin language of medicine is equally daunting. This chapter attempts to surmount the language barrier by translating ideas, philosophy, and unfamiliar concepts into words while introducing only sufficient statistics, mathematics, and algorithms to be useful for the collaborating scientist.
Because this chapter is intended for a mixed audience, it focuses on the most common points of intersection between cardiac surgery and quantitative science, with the goal of establishing sufficient common ground for effective and efficient collaboration. As such, it is not a substitute for statistical texts or academic courses, nor a substitute for the surgeon-investigator to establish a collaborative relationship with biostatisticians, nor is it intended to equip surgeons with sufficient statistical expertise to conduct highly sophisticated data analyses themselves.
At least three factors have contributed to evolution of Chapter 6 from edition to edition of this book: increasing importance of computers in analyzing clinical data, introduction of new and increasingly appropriate and applicable methods for analyzing those data, and growing importance of nontraditional machine learning methods for mining medical data.
Thus, the title of this chapter in Edition 1 was “Surgical Concepts, Research Methods, and Data Analysis and Use.” Its sections highlighted (1) surgical success and failure, (2) incremental risk factors, (3) research methods, (4) methods of data presentation and analysis and comparison, (5) decision making for individual patients, and (6) improving results of cardiac surgery. All remain important, but progress in each of these areas warrants a fresh approach. In the first edition, formulae were provided for surgeons to implement on a new generation of programmable calculators. These programs provided confidence limits and simple statistical tests that continue to be valuable, particularly in reading and evaluating the literature; however, with the passage of time, increasing sophistication and complexity of programmable calculators have taken implementation of the programs out of the reach of most surgeons. Therefore, we have eliminated those appendices.
In Edition 2, an organizing schema for clinical research was developed, and the name of the chapter was changed to reflect it: “The Generation of Knowledge from Information, Data, and Analyses.” But this schema did not lead to a matching organizational format for the chapter; it paved the way for one. At the time of its writing, there was explosive progress in techniques for analyzing time-related events, so an important portion of the chapter was devoted to this topic. Effective analysis of time-related events was no longer possible with programmable calculators; they demanded powerful computer resources.
In Edition 3, the progression from information to data to analyses to knowledge became the explicit organizing schema for the chapter. Sophisticated methods for longitudinal data analyses and comparative effectiveness assessment were introduced. Whereas the statistician was once the surgeon's primary collaborator in data analysis, that edition introduced computer scientists and mathematicians as partners in collaborative research.
In this edition we introduce other collaborators in the fields of artificial intelligence, ontology, and machine learning. In doing so, we expand themes hinted at in the third edition and hint at new techniques on the horizon. This edition is also strongly influenced by the Institute of Medicine's (IOM) Learning Healthcare System initiative and comparative effectiveness emphases of the IOM and NIH. Undoubtedly, evolution of this chapter will continue in subsequent editions, because new methods are constantly being developed to better answer clinical questions.
The organizational basis for this chapter is the Newtonian inductive method of discovery. It begins with information about a microcosm of medicine, proceeds to translation of information into data and analysis of those data, and ends with new knowledge about a small aspect of nature. This organizational basis emphasizes the phrase, “Let the data speak for themselves.” It is that philosophy that dictates, for example, placing “Indications for Operation” after, not before, presentation of surgical results throughout this book.
In health care, information is a collection of material, workflow documentation, and recorded observations (see Section II ). Information may be recorded in paper-based medical records or in electronic (computer) format.
Data consist of organized values for variables, usually expressed symbolically (e.g., numerically) by means of a controlled vocabulary (see Section III ). Characterization of data includes descriptive statistics that summarize parts or all of the data and express their variability.
Analysis is a process, often prolonged and repeated (iterative), that uses a large repertoire of methods by which data are explored, important findings are revealed and unimportant ones suppressed, and relations are clarified and quantified (see Sections IV and VI).
Knowledge is the synthesis of information, data, and analyses arrived at by inductive reasoning (see Section V ). However, generation of new knowledge does not occur in a vacuum; an important step is assimilating new knowledge within the body of existing knowledge.
New knowledge may take the form of clinical inferences , which are simple summarizing statements that synthesize information, data, and analyses, drawn with varying degrees of confidence that they are true. It may also include speculations , which are statements suggested by the data or by reasoning, often about mechanisms, without direct supportive data. Ideally, it also includes new hypotheses , which are testable statements suggested by reasoning or inferences from the information, data, and analyses.
New knowledge can be applied to a number of processes in health care, including (1) generating new concepts, (2) making individual patient care decisions, (3) obtaining informed consent from patients, (4) improving surgical outcomes, (5) assessing the quality and appropriateness of care, and (6) making regulatory decisions (see Section V ).
Unlike most chapters in this book, whose various parts can be read somewhat randomly and in isolation, Section I of this chapter should be read in its entirety before embarking on other sections. It identifies the mindset of the authors; defends the rationale for emphasizing surgical success and failure; contrasts philosophies, concepts, and ideas that shape both how we think about the results of research and how we do research; lays out a technique for successful clinical research that parallels the surgical technique portions of other chapters; and for collaborating statisticians, mathematicians, and computer scientists engaged in analyzing clinical data, lays the foundation for our recommendations concerning data analysis.
Much of the material in this introductory section is amplified in later portions of the chapter, and we provide cross-references to these to avoid redundancy.
Many forces drive the generation of new knowledge in cardiac surgery, including the economics of health care, need for innovation, clinical research, surgical success and failure, and awareness of medical error.
The economics of health care are driving changes in practice toward what is hoped to be less expensive, more efficient, yet higher quality care. Interesting methods for testing the validity of these claims have become available in the form of cluster randomized trials. In such trials (e.g., a trial introducing a change in physician behavior), patients are not randomized, physicians are (patients form the cluster being cared for by each physician)! This leads to inefficient studies that nevertheless can be effective with proper design and a large enough pool of physicians. It is a study design in which the unit of randomization (physician) is not the unit of analysis (individual patient outcome). Such trials appear to require rethinking of traditional medical ethics.
Just when it seems that cardiac surgery has matured, innovation intervenes and drives new knowledge, both from proponents and opponents. Innovation occurs at several levels. It includes new devices; new procedures; existing procedures performed on new groups of patients, such as the elderly and the fetus; simplifying and codifying seemingly disparate anatomy, physiology, or operative techniques; standardizing procedures to make them teachable and reproducible; and introducing new concepts of patient care (the intensive care unit, automated infusion devices, automated care by computer-based protocols). Many of these innovations have had applications beyond the boundary of cardiac surgery.
Yet, innovation is often at odds with cost reduction and is perceived as being at odds with traditional research. In all areas of science, however, injection of innovation is the enthalpy that prevents entropy, stimulating yet more research and development and more innovation. Without it, cardiac surgery would be unable to adapt to changes in managing ischemic heart disease, potential reversal of the atherosclerotic process, percutaneous approaches to valvar and congenital heart disease, and other changes directed toward less invasive therapy.
What is controversial is (1) when and if it is appropriate to subject innovation to formal clinical trial and (2) the ethics of innovation in surgery, for which standardization is difficult.
New knowledge in cardiac surgery has been driven from its inception by a genuine quest to fill voids of the unknown, whether by clinical research or laboratory research (which we do not emphasize in this chapter, although the principles and recipe for success are the same as for clinical research). This has included research to clarify both normal and abnormal physiology, but also to characterize the abnormal state of the body supported on cardiopulmonary bypass.
Clinical research has historically followed one of two broad designs: randomized clinical trials and nonrandomized studies of cohorts of patients (“clinical practice”), as detailed later in this section under “ Clinical Trials with Randomly Assigned Treatment ” and “ Clinical Studies with Nonrandomly Assigned Treatment ,” respectively. Increasing emphasis, however, is being placed on translational research—that is, bringing basic research findings to the bedside. John Kirklin called this the “excitement at the interface of disciplines.” Part and parcel of the incremental risk factor concept (see “ Incremental Risk Factor Concept ” in Section IV ) is that it is an essential link in a feedback loop that starts with surgical failure, proceeds to identifying risk factors, draws inferences about specific gaps in knowledge that need to be addressed by basic science, generates fundamental knowledge by the basic scientists, and ends by bringing these full circle to the clinical arena, testing and assessing the value of the new knowledge generated for improving medical care.
Results of operative intervention in heart disease, particularly surgical failure, drive much of the new knowledge generated by clinical research. In the late 1970s and early 1980s, a useful concept arose about surgical failures. That is, in the absence of natural disaster or sabotage, there are two principal causes of failure of cardiac operations (or other treatments) to provide a desired outcome for an individual patient: (1) lack of scientific progress and (2) human error.
The utility of this concept is that it leads to the programmatic strategies of research on the one hand and development on the other. Thus, lack of scientific progress is gradually reduced by generating new knowledge (research), and human error is reduced in frequency and consequences by implementing available knowledge (development), a process as vital in cardiac surgery as it is in the transportation and manufacturing sectors.
Increased awareness of medical error is driving the generation of new knowledge, just as it is driving increasing regulatory pressure and medicolegal litigation. The UAB group was one of the first to publish information about human error in cardiac surgery and place it into the context of cognitive sciences, human factors, and safety research. This interface of disciplines is essential for facilitating substantial reduction in injury from medical errors.
Surgical failure has been a strong stimulant of clinical research aimed at making scientific progress. With increasing requirements for reporting both outcomes and process measures in the United States (with “pay for performance”), there is now also an economic stimulus to reduce human error. The term “human error” carries negative connotations that make it difficult to discuss in a positive, objective way in order to do a root-cause analysis of surgical failures. It is too often equated with negligence or malpractice, and almost inevitably leads to blame of persons on the “sharp end” (caregivers), with little consideration of the decision making, organizational structures, infrastructures, or other factors that are remote in time and distance (“blunt end”).
As early as 1912, Richardson recognized the need to eliminate “preventable disaster from surgery.” Human errors as a cause of surgical failure are not difficult to find, particularly if one is careful to include errors of diagnosis, delay in therapy, inappropriate operations, omissions of therapy, and breaches of protocol.
When we initially delved into what was known about human error in the era before Canary Island (1977), Three-Mile Island (1979), Bhopal (1984), Challenger (1986), and Chernobyl (1986), events that contributed enormously to knowledge of the nature of human error, we learned two lessons from the investigation of occupational and mining injuries. First, successful investigation of the role of the human element in injury depends on establishing an environment of non-culpable error . The natural human reaction to investigation of error is to become defensive and provide no information that might prove incriminating. An atmosphere of blame impedes investigating, understanding, and preventing error. How foreign this is from the culture of medicine! We take responsibility for whatever happens to our patients as a philosophical commitment. Yet cardiac operations are performed in a complex and imperfect environment in which every individual performs imperfectly at times. It is too easy when things go wrong to look for someone to blame. Blame by 20/20 hindsight allows many root causes to be overlooked.
Second, we learned that errors of omission exceed errors of commission . This is exactly what we found in ventricular septal defect (VSD) repair ( Table 6-1 ), suggesting that the cardiac surgical environment is not so different from that of a gold mine, and we can learn from that literature.
| Error | Number |
|---|---|
| Operation despite severe pulmonary arterial disease | 3 |
| Undiagnosed and overlooked ventricular septal defects | 8 |
| Despite heart block, no permanent pacing electrodes inserted at operation | 1 |
| Clots in oxygenator and heat exchanger (and circle of Willis) | 1 |
| Extubation without reintubation within a few hours of operation in seriously ill infants | 4 |
| Self-extubation without reintubation in the face of low cardiac output | 1 |
| Transfusion of packed red blood cells of wrong type | 1 |
These two lessons reinforced some surgical practices and stimulated introduction of others that were valuable in the early stages of growth of the UAB cardiac surgery program: using hand signals for passing instruments, minimizing distractions, replying simply to every command, reading aloud the protocol for the operation as it proceeds, standardizing apparently disparate operations or portions thereof, and focusing morbidity conferences candidly on human error and lack of knowledge to prevent the same failure in the future. To amplify, these practices might be enunciated as a “culture of clarity”—in today's terms, a culture of transparency—the end result of which is a reproducible and successful surgical endeavor. In the operating room, each individual on the surgical team is relaxed but alert:
Hand signals serve to inform assistants and the scrub nurse of anticipated needs for a relatively small number of frequently used instruments or maneuvers.
Spoken communication is reserved for those out of the field of sight (i.e., the anesthesiologist and perfusionist). When verbalized, “commands” are acknowledged with a simple reply: “thank you,” “roger,” “yes.” Even those individuals out of the field learn to anticipate these events or commands.
Anticipated deviations from the usual are presented a few minutes to a day or two before the event. (In teaching settings, residents are encouraged to write an operative plan in the preoperative note.) Unanticipated deviations are acknowledged to all concerned as soon as possible.
Successful routines are codified. These include chronology for anticoagulation and its reversal, myocardial management routines (induction of cardioplegia, intervals of cardioplegia reinfusion, controlled myocardial reperfusion before aortic clamp removal), and protocols controlled by the surgeon for commencing and weaning the patient from cardiopulmonary bypass.
Technical intuitive concepts are articulated. For example, some think the VSD in tetralogy of Fallot is a circular hole. Thus, closing such a hole would simply involve running a suture circumferentially to secure a patch. Kirklin and Karp were able to describe the suture line as having four different areas of transition in three dimensions and precisely articulated names for those transitions. Each had a defined anatomic relationship to neighboring structures, so the hole became infinitely more interesting!
Discussion of surgical failure is planned for a time (e.g., Saturday morning) when distractions are minimal. The stated goal is improvement, measurable in terms of reproducibility and surgical success. The philosophy is that events do not simply occur but have antecedent associations, so-called root-cause analysis. An attempt is made to determine if errors can be avoided and if scientific knowledge exists or does not exist to prevent future failure.
A major portion of the remainder of this chapter addresses acquisition and description of this new knowledge.
Slips are failures in execution of actions and are commonly associated with attention failures ( Box 6-2 ). Some external stimulus interrupts a sequence of actions or in some other way intrudes into them such that attention is redirected. In that instance, the intended action is not taken. Lapses are failures of memory. A step in the plan is omitted, one's place in a sequence of actions is lost, or the reason for what one is doing is forgotten. Mistakes relate to plans and so take two familiar forms: (1) misapplication to the immediate situation of a good plan (rule) appropriate for a different and more usual situation and (2) application of the wrong plan (rule).
Largely based on definitions by James Reason, these terms are used in a technical fashion by cognitive scientists studying human error.
Failure of a planned sequence of mental or physical activities to achieve its intended outcome in the absence of intervention of a chance agency to which the outcome can be attributed.
Failure in the execution of an intended action sequence, whether or not the plan guiding it was adequate to achieve its purpose.
Failure in the storage stage (memory) of an action sequence, whether or not the plan guiding it was adequate to achieve its purpose.
Failure or deficiency of judgment or inference involved in selecting an objective or specifying the means of achieving it, regardless of whether actions directed by these decisions run according to plan.
Slips and lapses constitute active errors . They occur at the physician-patient interface. Mistakes, in addition, constitute many latent errors . These are indirect errors that relate to performance by leaders, decision makers, managers, certifying boards, environmental services, and a host of activities that share a common trait: planning, decisions, ideas, and philosophy removed in time and space from the immediate healthcare environment in which the error occurred (blunt end). These are a category of error over which the surgeon caring for a patient (sharp end) has little or no control or chance of modifying because latent errors are embedded in the system. It is claimed by students of human error in other contexts that the greatest chance of preventing adverse outcomes from human error is in discovering and neutralizing latent error.
If one considers all the possibilities for error in daily life, what is remarkable is that so few are made. We are surrounded with unimaginable complexity, yet we cope nearly perfectly because our minds simplify complex information. Think of how remarkably accident-free are our early-morning commutes to the hospital while driving complex machines in complex traffic patterns.
When this cognitive strategy fails, it does so in only a few stereotypical ways. Because of this, models have been developed, based largely on observation of human error, that mimic human behavior by incorporating a fallible information-handling device (our minds) that operates correctly nearly always, but is occasionally wrong. Central to the theory on which these models are based is that our minds can remarkably simplify complex information. Exceedingly rare imperfect performance is theorized to be the price we pay for being able to cope, probably nearly limitlessly, with complexity. The mechanisms of human error are purported to stem from three aspects of “fallible machines”: downregulation, upregulation, and primitive mechanisms of information retrieval. In the text that follows, we borrow heavily from the human factors work of James Reason.
We call this habit formation, skill development, and “good hands.” Most activities of life, and certainly those of a skillful surgeon, need to become automatic. If we had to think about every motion involved in driving a car or performing an operation, the task would become nearly impossible to accomplish accurately. It would not be executed smoothly and would be error prone. It is hard to quantify surgical skill. It starts with a baseline of necessary sensory-motor eye-hand coordination that is likely innate. It becomes optimized by aggregation of correct “moves” and steps as well as by observation. It is refined by repetition of correct actions, implying identification of satisfactory and unsatisfactory immediate results (feedback). Then comes individual reflection and codification of moves and steps by hard analysis. Finally, motor skills are mastered by a synthesis of cognition and motor memory. The resulting automaticity and reproducibility of a skillful surgeon make a complex operation appear effortless, graceful, and flawless. However, automaticity renders errors inevitable.
Skill-based errors occur in the setting of routine activity. They occur when attention is diverted (distraction or preoccupation) or when a situation changes and is not detected in a timely fashion. They also occur as a result of overattention. Skill-based errors are ones that only skilled experts can make—beautiful execution of the wrong thing (slip) or failure to follow a complex sequence of actions (lapse). Skill-based errors tend to be easily detected and corrected.
Rule-based errors occur during routine problem-solving activities. Goals of training programs are to produce not only skillful surgeons but also expert problem solvers. Indeed, an expert may be defined as an individual with a wide repertoire of stored problem-solving plans or rules. Inevitable errors that occur take the form of either inappropriate application of a good rule or application of a bad rule.
Our mind focuses conscious attention on the problem or activity with which we are confronted and filters out distracting information. The price we pay for this powerful ability is susceptibility to both data loss and information overload. This aspect of the mind is also what permits distractions or preoccupations to capture the attention of the surgeon, who would otherwise be focused on the routine tasks at hand. In problem solving, there may be inappropriate matching of the patient's actual condition to routine rules for a somewhat different set of circumstances. Some of the mismatch undoubtedly results from the display of vast quantities of undigested monitored information about the patient's condition. Errors of information overload need to be addressed by more intelligent computer-based assimilation and display of data.
The mind seems to possess an unlimited capacity for information storage and a blinding speed of information retrieval unparalleled by computers. In computer systems, there is often a trade-off between storage capacity and speed of retrieval; not so for the mind. The brain achieves this, apparently, not by storing facts but by storing models and theories—abstractions—about these facts (i.e., it stores meaning rather than data behind the meaning). Furthermore, the information is stored in finite packets along with other, often unrelated, information. (Many people use the latter phenomenon to recall names, for example, by associating them with more familiar objects such as animals.) The implications for error are that our mental image may diverge importantly from reality.
The mind's search strategy for information achieves remarkable speed by having apparently just two tools for fetching information. First, it matches patterns. Opportunity for error arises because our interpretation of the present and anticipation of the future are shaped by patterns or regularities of the past. Second, if pattern matching produces multiple items, it prioritizes these by choosing the one that has been retrieved most often. This mechanism gives rise to rule-based errors, for example, in a less frequently occurring setting.
When automatic skills and stored rules are of no help, we must consciously think. Unlike the automaticity we have just described, the conscious mind is of limited capacity but possesses powerful computational and reasoning tools, all those attributes we ascribe to the thought process. However, it is a serial, slow, and laborious process that gives rise to knowledge-based errors . Unlike stereotypical skill- and rule-based errors, knowledge-based errors are less predictable. Furthermore, there are far fewer opportunities in life for “thinking” than for automatic processes, and therefore the ratio of errors to opportunity is higher. Errors take the form of confirmation bias, causality vs. association, inappropriate selectivity, overconfidence, and difficulties in assimilating temporal processes.
The unusual ordering of material presented in the clinical chapters of this book was chosen by its original authors to provide a framework for thinking with the conscious mind about heart disease and its surgical therapy that would assist in preventing knowledge-based errors. For example, an algorithm (protocol, recipe) for successfully managing mitral valve regurgitation is based on knowledge of morphology, etiology, and detailed mechanisms of the regurgitation; preoperative clinical, physiologic, and imaging findings; natural history of the disease if left untreated; technical details of operation; postoperative management; both early and long-term results of operation; and from all these considerations, the indications for operation and type of operation. Lack of adequate knowledge results in inappropriate use of mitral valve repair, too many mitral valve replacements, or suboptimal timing of operation.
We have presented this cognitive model in part because it suggests constructive steps for reducing human error and, thus, surgical failure.
It affirms the necessity for intense apprentice-type training that leads to automatization of surgical skill and problem-solving rules. It equally suggests the value of simulators for acquiring such skills. It supports creation of an environment that minimizes or masks potential distractions. It supports a system that discovers errors and allows recovery from them before injury occurs. This requires a well-trained team in which each individual is familiar with the operative protocol and is alert to any departures from it. In this regard, deLeval and colleagues’ findings are sobering. Major errors were often realized and corrected by the surgical team, but minor ones were not, and the number of minor errors was strongly associated with adverse outcomes. It was also sobering that self-reporting of intraoperative errors was of no value. Must there be a human factors professional at the elbow of every surgeon and physician?
James Reason suggested that other “cognitive prostheses” may be of value, some of which are being advocated in medicine. For example, there is much computers can do to reduce medication errors. A prime target is knowledge-based errors. Reducing these errors may not be achievable through computer artificial intelligence, but rather through more appropriate modes of information assembly, processing, and display for processing by the human mind. Finally, if latent errors are the root cause of many active errors, analysis and correction at the system level will be required. A cardiac surgery program may fail, for example, from latent errors traceable to management of the blood bank, postoperative care practices, ventilation systems, and even complex administrative decisions at the level of hospitals, universities with which they may be associated, and national health system policies and regulations within which they operate.
A practical consequence of categorizing surgical failures into two causes is that they fit the programmatic paradigm of “research and development”: discovery on the one hand and application of knowledge to prevent failures on the other. The quest to reduce injury from medical errors that has just been described is what we might term “development.” The remainder of this chapter focuses mainly on the portion of the paradigm that is research, but also more narrowly on clinical research .
Clinical research in cardiac surgery as emphasized in this chapter consists largely of patient-oriented investigations motivated by a serious quest for new knowledge to improve surgical results—that is, to increase survival early and long term; to reduce complications; to enhance quality of life; to extend appropriate operations to more patients, such as high-risk subsets; and to devise and evaluate new beneficial procedures that have been generalized into a strategy of managing not so much individual malformations as a physiologic situation (e.g., the Fontan operation and its variants [see Chapter 41 ] and the Norwood operation [see Chapter 49 ]).
This inferential activity, aimed at improving clinical results, is in contrast to pure description of experiences. Its motivation also contrasts with those aspects of “outcomes assessment” motivated by regulation or punishment, institutional promotion or protection, quality assessment by outlier identification, and negative aspects of cost justification or containment. These coexisting motivations have stimulated us to identify, articulate, and contrast philosophies that underlie serious clinical research. It is these philosophies that inform our approach to analysis of clinical experiences.
“Let the data speak for themselves.”
Arguably, Sir Isaac Newton's greatest contribution to science was a novel intellectual tool: a method for investigating the nature of natural phenomena. His contemporaries considered his method not only a powerful scientific investigative tool, but also a new way of philosophizing applicable to all areas of human knowledge. His method had two strictly ordered aspects that for the first time were truly systematically expressed: a first, and extensive, phase of data analysis whereby observations of some small portion of a natural phenomenon are examined and dissected, followed by a second, less emphasized, phase of synthesis whereby possible causes are inferred and a small portion of nature revealed from the observations and analyses. This was the beginning of the inductive method in science: valuing first and foremost the observations made about a phenomenon, then “letting the data speak for themselves” in suggesting possible natural mechanisms.
This represented the antithesis of the deductive method of investigation that had been so successful in the development of mathematics and logic (the basis for ontology-based computer reasoning today). The deductive method begins with what is believed to be the nature of the universe (referred to by Newton as “hypothesis”), from which logical predictions are deduced and tested against observations. If the observations deviate from logic, the data are suspect, not the principles behind the deductions. The data do not speak for themselves.
Newton realized that it was impossible at any time or place to have complete knowledge of the universe. Therefore, a new methodology was necessary to examine just portions of nature, with less emphasis on synthesizing the whole. The idea was heralded as liberating in nearly all fields of science.
As the 18th century unfolded, the new method rapidly divided such diverse fields as religion into those based on deduction (fundamentalism) and those based on induction (liberalism), roughly Calvinism vs. Wesleyan-Arminianism. This philosophical dichotomy continues to shape not just the scientific but the social, economic, and political climate of the 21st century.
Determinism is the philosophy that everything—events, acts, diseases, decisions—is an inevitable consequence of causal antecedents: “Whatever will be will be.” If disease and patients’ response to disease and to disease treatment were clearly deterministic and inferences deductive, there would be no need to analyze clinical data to discover their general patterns. Great strides are being made in linking causal mechanisms to predictable clinical response (see Classification Methods in Section VI ). Yet many areas of cardiovascular medicine remain nondeterministic and incompletely understood. In particular, the relation between a specific patient's response to complex therapy such as a cardiac operation and known mechanisms of disease appears to be predictable only in a probabilistic sense. For these patients, therapy is based on empirical recognition of general patterns of disease progression and observed response to therapy.
Generating new knowledge from clinical experiences consists, then, of inductive inference about the nature of disease and its treatment from analyses of ongoing empirical observations of clinical experience that take into account variability, uncertainty, and relationships among surrogate variables for causal mechanisms. Indeed, human error and its opposite—success—may be thought of as human performance variability.
To better convey how new knowledge is acquired from observing clinical experiences, we look back to the 17th century to encounter the proverbial dichotomy between collectivism and individualism, so-called lumpers and splitters or forests and trees.
In 1603 during one of its worst plague epidemics, the City of London began prospective collection of weekly records of christenings and burials. In modern language, this was an administrative database or registry (see Box 6-1 ). Those “who constantly took in the weekly bills of mortality made little use of them, than to look at the foot, how the burials increased or decreased; and among the casualties, what has happened rare, and extraordinary, in the week current,” complained John Graunt. Unlike those who stopped at counting and relating anecdotal information, Graunt believed the data could be analyzed in a way that would yield useful inferences about the nature and possible control of the plague.
His ultimate success might be attributed in part to his being an investigator at the interface of disciplines. By profession he was a haberdasher, so Graunt translated merchandise inventory dynamics into terms of human population dynamics. He described the rate of goods received (birth rate) and the rate of goods sold (death rate); he then calculated the inventory (those currently alive).
Graunt then made a giant intellectual leap. In modern terms, he assumed that any item on the shelf was interchangeable with any other (collectivism). By assuming, no matter how politically and sociologically incorrect, that people are interchangeable, he achieved an understanding of the general nature of the birth-life-death process in the absence of dealing with specific named individuals (individualism). He attempted to discover, as it were, the general nature of the forest at the expense of the individual trees.
Graunt then identified general factors associated with variability of these rates (risk factors, in modern terminology; see Multivariable Analysis in Section IV ). From the City of London Bills of Mortality, he found that the death rate was higher when ships from foreign ports docked in the more densely populated areas of the city, and in households harboring domestic animals. Based on these observations, he made inferences about the nature of the plague—what it was and what it was not—and formulated recommendations for stopping its spread. They were crude, nonspecific, and empirical: avoid night air brought in from foreign ships (which we now know is not night air but rats), flee to the country, separate people from animal vectors, and quarantine infected individuals. Nevertheless, they were effective in stopping the plague for 200 years until its cause and mechanism of spread were identified.
Lessons based on this therapeutic triumph of clinical investigation conducted more than 300 years ago include the following: (1) empirical identification of patterns of disease can suggest fruitful directions for future research and eliminate some hypothesized causal mechanisms, (2) recommendations based on empirical observations may be effective until causal mechanisms and treatments are discovered, and (3) new knowledge is often generated by overview (synthesis), as well as by study of individual patients.
When generating new knowledge about the nature of heart disease and its treatment, it is important both to examine groups of patients (the forest) and to investigate individual therapeutic failures (the trees). This is similar to Heisenberg's uncertainty principle in chemistry, thermodynamics, and mechanics, in which physical matter and energy can be thought of as discrete particles on the microhierarchical plane (individualism, splitting, trees), and as waves (field theory) on the macrohierarchical plane (collectivism, lumping, forests). Both views give valuable insights into nature, but they cannot be viewed simultaneously. Statistical methods emphasizing optimum discrimination for identifying individual patients at risk tend to apply to the former, whereas those emphasizing probabilities and general inferences tend to apply to the latter.
When we turn our focus from named individuals experiencing surgical failure to groups of patients, data analysis becomes mandatory to discover relationships between outcome and items that differ in value from patient to patient (called variables ). A challenge immediately arises: Many of the variables related to outcome are measured either on an ordered clinical scale (ordinal variables), such as New York Heart Association (NYHA) functional class, or on a more or less unlimited scale (continuous variables), such as age. Three hundred years after Graunt, the Framingham Heart Disease Epidemiology Study investigators were faced with this frustrating problem. Many of the variables associated with development of heart disease were continuously distributed ones, such as age, blood pressure, and cholesterol level. To examine the relationship of such variables to development of heart disease, it was then accepted practice to categorize continuous variables coarsely and arbitrarily for cross-tabulation tables. Valuable information was lost this way. Investigators recognized that a 59-year-old's risk of developing heart disease was more closely related to that of a 60-year-old's than to that of the group of patients in the sixth vs. seventh decade of life. They therefore insisted on examining the entire spectrum of continuous variables rather than subclassifying the information.
What they embraced is a key concept in the history of ideas—namely, continuity in nature . The idea has emerged in mathematics, science, philosophy, history, and theology. In our view, the common practice of stratifying age and other more or less continuous variables into a few discrete categories is lamentable because it loses the power of continuity (some statisticians call this “borrowing power”). Focus on small, presumed homogeneous groups of patients also loses the power inherent in a wide spectrum of heterogeneous but related cases. After all, any trend observed over an ever-narrower framework looks more and more like no trend at all! Like the Framingham investigators, we therefore embrace continuity in nature unless it can be demonstrated that doing so is not valid, useful, or beneficial. (Modern methods of machine learning that use classification methods may seem to stumble at this point, but repetition of analyses over thousands of sampled data sets combined with averaging achieves a close approximation to continuity in nature; see Classification Methods in Section VI .)
The second problem the Framingham investigators addressed was the need to consider multiple variables simultaneously. Univariable (one variable at a time) statistics are attractive because they are simple to understand. However, most clinical problems are multifactorial. At the same time, clinical data contain enormous redundancies that somehow need to be taken into account (e.g., height, weight, body surface area, and body mass index are highly correlated and relate to the conceptual variable “body size”).
Cornfield came to the rescue of the Framingham investigators with a new methodology called multivariable logistic regression (see “ Logistic Regression Analysis ” in Section IV ). It permitted multiple factors to be examined simultaneously, took into account redundancy of information among variables (covariance), and identified a parsimonious set of variables for which the investigators coined the term “factors of risk” or risk factors (see “ Parsimony versus Complexity ” later in this section and Multivariable Analysis in Section IV ).
Various forms of multivariable analysis, in addition to logistic regression analysis, have become available to clinical investigators. Their common theme is to identify patterns of relationships between outcome and a number of variables considered simultaneously. These are not cause-effect relations, but associations with underlying causal mechanisms (see discussion of surrogates under Multivariable Analyses in Section IV ). The relationships that are found may well be spurious, fortuitous, hard to interpret, and even confusing because of the degree of correlation among variables. For example, women may be at a higher risk of mortality after certain cardiac procedures, but female gender may not be a “risk factor,” because other factors, such as body mass index, may be the more general variable related to risk, whether in women or men. Even so, it is simultaneously true that (1) being female is not per se a risk factor, but (2) women are at higher risk by virtue of the fact that on average they are smaller than men.
This means that a close collaboration must exist between statistical experts and surgeons, particularly in organizing variables for analysis.
Risk factor methodology introduced another complexity besides increased dimensionality. The logistic equation is a symmetric S-shaped curve that expresses the relationship between a scale of risk, called logit units , and a corresponding scale of absolute probability of experiencing an event ( Fig. 6-1 ). Because the relationship is not linear, it is not possible to simply add up scores for individual variables and come up with a probability of an event, a technique that has been attempted in other settings (see Risk Stratification in Section VI ).
 to absolute probability of an event. A, Logistic relation, shown when risk factors are translated into logit units, B16 is depicted along horizontal axis, and probability of the outcome event along vertical axis. Logistic equation is inserted, where exp is the natural exponential function. B, Relation between cardiac index and probability of hospital death in cardiac failure determined by logistic regression analysis of data obtained in intensive care unit (UAB). Cardiac index in L · min −1 · m −2 is plotted along the horizontal axis. z describes the transformation of cardiac index to logit units, where Ln is the natural logarithm. If data were replotted with transformation to logit units along the horizontal axis, depiction would reflect some portion of the curve in A .")
The nonlinear relationship between risk factors and probability of outcome makes medical sense. Imagine a risk factor with a logit unit coefficient of 1.0 (representing an odds ratio of 2.7; Box 6-3 and see Fig. 6-1 ). If all other things position a patient far to the left on the logit scale, a 1-logit-unit increase in risk results in a trivial increase in the probability of experiencing an event. But as other factors move a patient closer to the center of the scale (0 logit units, corresponding to a 50% probability of an event), a 1-logit-unit increase in risk makes a huge difference. This is consistent with the medical perception that some patients experiencing the same disease, trauma, or complication respond quite differently. Some are medically robust because they are far to the left (low-risk region) on the logit curve before the event occurred. Others are medically fragile because their age or comorbid conditions place them close to the center of the logit curve. For the latter, a 1-logit-unit increase in risk can be “the straw that breaks the camel's back.” It is this kind of relation that makes it hard to demonstrate, for example, the benefit of bilateral internal thoracic artery grafting in relatively young adults followed for even a couple of decades, but easy in patients who have other risk factors. The same has been demonstrated for risk of operation in patients with aortic regurgitation and low ejection fraction.
Consider two groups of patients, A and B. Mortality in group A is 10 of 40 patients (25%); in B, it is 5 of 50 patients (10%). For the sake of illustrating the various ways these proportions (see Box 6-13 ), 0.25 and 0.10, can be expressed relative to one another, designate a as the number of deaths (10) in A and b as the number alive (30). The total in A is a+b (40) patients, n A . Designate c as the number of deaths (5) in B and d as the number alive (45). The total in B is c+d (50) patients, n B . Designate P A as the proportion of deaths in A, a/(a+b) or a/n A , and P B as the proportion in B, c/(c+d) or c/n B .
Relative risk is the ratio of two probabilities. In the example above, relative risk of A compared with B is P A /P B = [ a/ ( a+b )] / [ c /( c+d )] = 0.25/0.10 or 2.5. Equivalently, one could reverse the proportions, P B /P A = 0.10/0.25 = 0.4. If P A were to exactly equal P B , relative risk would be unity (1.0). Another way to express relative risk when comparing two treatments is by relative risk reduction , which for relative risks greater than 1 is 1 minus relative risk. This is mathematically identical to dividing the absolute difference in proportions by the higher of the two: (P B − P A )/P B .
The odds of an event is the number of events divided by non-events. In the example above, the odds of death in A is a/b = 10/30 = 0.33; in B, it is c/d = 5/45 = 0.11. The mathematical interrelation of probability ( P ) of an event and odds ( O ) are these: O = P/ (1 − P ) and P = O/ (1 + O ). A probability of 0.1 is an odds of 0.11, but a probability of 0.5 is an odds of 1, of 0.8 an odds of 4, of 0.9 an odds of 9, and of 1.0 an odds of infinity. Often, it is interesting to examine the odds of the complement (1 − P ) of a proportion, (1 − P)/P, which is gambler's odds . Thus, a P value of .05 is equivalent to an odds of .053 and a gambler's odds of 19 : 1. A P value of .01 has a gambler's odds of 99 : 1, and a P value of 2 has a gambler's odds of 4 : 1.
The odds ratio is the ratio of odds. In the above example, the odds ratio of A compared with B is (a/b)/(c/d) = ad/bc, which is either (10/30)/(5/45) = 3 or (10 · 45)/(30 · 5) = 3.
Note that the logistic equation is Ln[ P /(1 − P )]. For A, P A /(1 − P B ) is a/b, the odds of A. Thus, Ln[ P/ (1 − P )] is log odds. Logistic regression can then be thought of as an analysis of log odds. Exponentiation of a logistic coefficient for a dichotomous (yes/no) risk factor from such an analysis re-expresses it in terms of the odds ratio for those with versus those without the risk factor (see Box 6-5 ).
When the probability of an event is low, say less than 10%, relative risk (RR) and the odds ratio (OR) are numerically nearly the same. The mathematical relation is RR = [(1 −P A /(1 − P B ) ] · OR. In the above example, the relative risk was 2.5, but the odds ratio was 3, and the disparity increases as the probability of event increases to 50%.
Relative risk is easier for most physicians to grasp because it is simply the ratio of proportions. It is unusual to encounter a physician without an epidemiology background who understands the odds ratio.
Both relative risk and odds ratios are expressed on a scale of 0 to infinity. However, all odds ratios less than 1 are squeezed into the range 0 to 1, in contrast to those greater than 1, which are spread out from 1 to infinity. It is thus difficult to visualize that an odds ratio of 4 is equivalent to one of 0.25 if a linear scale is used. We recommend that a scale be chosen to express these quantities with equal distance above and below 1.0. This can be achieved, for example, by using a logarithmic or logit presentation scale.
The risk difference is the difference between two proportions. In the above example, P A − P B is the risk difference. In many situations, risk difference is more meaningful than risk ratios (either relative risk or the odds ratio). Consider a low probability situation with a risk of 0.5% and another with a risk of 1%. Relative risk is 2. Yet risk difference is only 0.5%. In contrast, consider a higher-probability situation in which one probability is 50% and the other 25%. Relative risk is still 2, but risk difference is 25%. These represent the proverbial statement that “twice nothing is still nothing.” They reflect the relation between the logit scale and absolute probability (see Fig. 6-1, A ), recalling that the logit scale is one of log odds.
An alternative way to express a difference in probabilities when the difference is arranged to be positive (e.g., P A − P B ), and thus expresses absolute risk reduction, is as the inverse, 1/ (P A − P B ). This expression of absolute risk reduction is called number to treat. It is useful in many comparisons in which it is meaningful to answer the question, “How many patients must be treated by A (compared with B) to prevent one event (death)?” In our example, absolute risk reduction is 25% − 10% = 15%, and number needed to treat is 1/0.15 = 6.7. Number needed to treat is particularly valuable for thinking about risks and benefits of different treatment strategies. If it is large, one may question the risk of switching treatments, but if it is small, the benefit of doing so becomes more compelling.
In time-related analyses, it is convenient to express the model of risk factors in terms of a log-linear function (see Box 6-5 and “ Cox Proportional Hazards Regression ” in Section IV ): Ln(λ t ) = Ln(λ t ) β 0 + β 1 x 1 … β k x k , where Ln is the natural logarithm and λ t is the hazard function. The regression coefficients, β , for a dichotomous risk factor thus represent the logarithm of the ratio of hazard functions. Hazard ratios, as well as relative risk and the odds ratio, can be misleading in magnitude (large ratios, small risk differences) in some settings. Hazard comparisons, just like survival comparisons, often are more meaningfully and simply expressed as differences.
This type of sensible, nonlinear medical relation makes us want to deal with absolute risk rather than relative risk or risk ratios (see Box 6-3 ). Relative risk is simply a translation of the scale of risk, without regard to location on that scale. Absolute risk integrates this with the totality of other risk factors.
Importantly, the Framingham investigators did not stop at risk factor identification. Because logistic regression generates an equation based on raw data, it can be solved for a given set of values for risk factors. The investigators devised a cardboard slide rule for use by lay persons to determine their predicted risk of developing heart disease within the next 5 years.
Whenever possible and appropriate, results of clinical data analyses should be expressed in the form of mathematical models that become equations. These can be solved after “plugging in” values for an individual patient's risk factors to estimate absolute risk and its confidence limits. Equations are compact and portable, so that with the ubiquitous computer, they can be used to advise individual patients (see “ Decision Making for Individual Patients ” in Section V ).
It can be argued that equations do not represent raw data. But in most cases, are we really interested in raw data? Archeologists are interested in the past, but the objective of most clinical investigation is not to predict the past, but to draw inferences based on observations of the past that can be used in treating future patients. Thus, one might argue that equations derived from raw data about the past are more useful than raw, undigested data.
One of the important advantages of generating equations is that they can be used to predict future results for either groups of patients or individual patients. We recognize that when speaking of individual patients, we are referring to a prediction concerning the probability of events for that patient; we generally cannot predict exactly who will experience an event or when an event will occur. Indeed, whenever we apply what we have learned from clinical experience or the laboratory to a new patient, we are predicting. This motivated us to develop statistical tools that yield patient-specific estimates of absolute risk as an integral byproduct. These were intended to be used for formal or informal comparison of predicted risks and benefits among alternative therapeutic strategies.
Of course, the nihilist will say, “You can't predict.” However, in a prospective study of 3720 patients in Leuven, Belgium, we generated evidence that predictions from multivariable equations are generally reliable (see “ Residual Risk ” in Section VI ). We compared observed survival, obtained at subsequent follow-up, with prospectively predicted survival. The correspondence was excellent in 92% of patients. However, it was poor in the rest ( Fig. 6-2 and Table 6-2 ; see also “ Residual Risk ” in Section VI ). A time-related analysis of residual risk identified circumstances leading to poor prediction and revealed the limitations of quantitative predictions: (1) When patients have important rare conditions that have not been considered in the analysis, risk is underestimated. (2) When large data sets rich in clinically relevant variables are the basis for prediction equations, prediction should be suspect in only a small proportion of patients with unaccounted-for conditions (see “ Residual Risk ” in Section VI for details). Except for these limitations, multivariable equations appear capable of adjusting well for different case mixes.
 compared with predicted survival. Each circle represents an observed death, positioned at time of death along horizontal axis, and according to Kaplan-Meier life table method along vertical axis; vertical bars are 70% confidence limits (CL). Solid line and its 70% CLs represent predicted survival. Notice systematic underestimation of survival. Number of predicted deaths = 273 (5.7%) and observed deaths = 243 (6.5%); P = .03. B, Patients stratified by presence (open squares) and absence (circles) of rare unaccounted-for risk factors (malignancy, preoperative dialysis, atrial fibrillation, ventricular tachycardia, or aortic regurgitation). Otherwise, format is as in A. Note excellent correspondence of predicted survival to observed survival in patients without these factors, and substantial underestimation of risk in patients with them.")
| Rare Risk Factors | Total Deaths | |||||
|---|---|---|---|---|---|---|
| Observed | Predicted | |||||
| n | No. | % | No. | % | P | |
| No | 3428 | 186 | 5.4 | 191 | 5.6 | .7 |
| Yes | 292 | 57 | 20 | 22 | 7.5 | <.0001 |
a Table illustrates both ability to predict from multivariable equations and pitfalls of doing so.
This analysis has important implications for “report card” registries used in institutional comparisons. Surgeons often object to these comparisons on the basis that risk adjustment (see Risk Adjustment in Section VI ) accounts for neither risk stratification (see Risk Stratification in Section VI ) nor rare combinations of risk factors that defy prediction. They may be correct. Unfortunately, in advising patients about operation, we find that these are the very individuals whose risk is difficult to predict on clinical grounds and for whom we wish we had good prediction equations.
The amount of data necessary to generate new knowledge is much larger than that needed to use the knowledge in a predictive way. To generate new knowledge, data should be rich both in relevant variables and in variables eventually found not to be relevant. But for prediction, one needs to collect only those variables used in the equation (see Risk Adjustment in Section VI ) unless one is interested in investigating reasons for lack of prediction (see Residual Risk in Section VI ).
A related use of predictive equations is in comparing alternative therapies. Some would argue that the only believable comparisons are those based on randomized trials, and that documented clinical experiences are irrelevant and misleading. However, many randomized trials are homogeneous and focused and are analyzed by blunt instruments, such as an overall effect. On the other hand, real-world clinical experience involves patient selection that is difficult to quantify, may be a single-institution experience with limited generality except to other institutions of the same variety, is not formalized unless there is prospective gathering of clinical information into registries, and is less disciplined. Nevertheless, analyses of clinical experiences can yield a fine dissecting instrument in the form of equations that are useful across the spectrum of heart disease for comparing alternative treatments and therefore for advising patients (see “ Clinical Studies with Nonrandomly Assigned Treatment ” later in this section).
Although clinical data analysis methods and results may seem complex at times, as in the large number of risk factors that must be assessed for comparing treatment strategies in ischemic heart disease, an important philosophy behind such analysis is parsimony (simplicity). We have discussed two reasons for this previously. One is that clinical data contain inherent redundancy, and one purpose of multivariable analysis is to identify that redundancy and thus simplify the dimensionality of the problem. A second reason is that assimilation of new knowledge is incomplete unless one can extract the essence of the information. Thus, clinical inferences are often even more digested and simpler than the multivariable analyses.
We must admit that simplicity is a virtue based on philosophical, not scientific, grounds. The concept was introduced by William of Ocken in the early 14th century as a concept of beauty—beauty of ideas and theories. Nevertheless, it is pervasive in science.
There are dangers associated with parsimony and beauty, however. The human brain appears to assimilate information in the form of models, not actual data (see “ Human Error ” earlier in this section). Thus, new ideas, innovations, breakthroughs, and new interpretations of the same data often hinge on discarding past paradigms (thinking “outside the box”). There are other dangers in striving for simplicity. We may miss important relations because our threshold for detecting them is too high. We may reduce complex clinical questions to simple but inadequate questions that we know how to answer.
For analyses whose primary purpose is comparison, it is important, when sufficient data are available ( Box 6-4 ), to account for “everything known.” In this way the residual variability attributed to the comparison is most likely to be correct.
A common misconception is that the larger the study group (called the sample because it is a sample of all patients past, present, and future; see later Box 6-13 ), the larger the amount of data available for analysis. However, in studies of outcome events, the effective sample size for analysis is proportional to the number of events that have occurred, not the size of the study group. Thus, a study of 200 patients experiencing 10 events has an effective sample size of 10, not 200.
Ability to detect differences in outcome is coupled with effective sample size. A statistical quantification of the ability to detect a difference is the power of a study. A few aspects of power that affect multivariable analyses of events are mentioned.
Many variables in a data set represent subgroups of patients, and some of them may be few in number. If a single patient in a small subgroup experiences an event, multivariable analysis may identify that subgroup as one at high risk, when in fact the variable represents only a specific patient, not a common denominator of risk (see “ Incremental Risk Factor Concept ” in Section IV ). The purpose of a multivariable analysis is to identify general risk factors, not individual patients experiencing events!
Thus, more than one event needs to be associated with every variable considered in the analysis. The rule of thumb in multivariable analysis is that the ratio of events to risk factors identified should be about 10 : 1. For us, sufficient data means at least five events associated with every variable. This strategy could result in identifying up to one factor per five events. We get nervous at this extreme, but in small studies we are sometimes close to that ratio. However, bear in mind that variables may be highly correlated and subgroups overlap, so in the course of analysis, the number of unexplained events in a subgroup may effectively fall below five, which is insufficient data.
Thus, there is both an upper limit of risk factors that can be identified by multivariable analysis and a lower limit of events to allow a variable to be considered in the analysis. Sufficient data implies having enough events available to test for all relevant risk factors.
The philosophies described so far focus on the challenge of generating new knowledge from clinical experiences. However, other uses are made of clinical data.
Clinical data may be used as a form of advertising. Innovation stems less from purposefulness than from aesthetically motivated curiosity, frustration with the status quo, sheer genius, fortuitous timing, favorable circumstances, and keen intuition. With innovation comes the need to promote. However, promotional records of achievement should not be confused with serious study of safety, clinical effectiveness, and long-range appropriateness.
Of growing importance is the use of clinical information for regulation or to gain institutional competitive advantage. Using clinical outcomes data to rank institutions or individual doctors has become popular in the United States (see Risk Stratification and Risk Adjustment in Section VI ). Many surgeons perceive clinical report cards as a means for punishment or regulation. What is troubling is that their use is based on a questionable quality-control model of outlier identification. Because doctors are people and not machines, this approach generates counterproductive ethical side effects, including defensiveness and hiding the truth. It hinders candid, non-accusatory (non-culpable), serious examination of medical processes for the express purpose of improving patient care (see “ Human Error ” earlier in this section).
Critics of clinical report cards charge that to improve their rankings, some institutions refuse to operate on sicker patients. In several studies of community hospitals by the UAB group, it was shown that they could indeed improve their risk-unadjusted rankings by restricting surgery to low-risk cases. However, their results in such patients were often inferior to those of institutions of excellence operating on similar low-risk patients. That is, their risk-adjusted mortality was high even for low-risk cases.
With the intense focus on institutional performance, another undesirable side effect of data analysis decried years ago has crept back in: undue emphasis on hospital mortality and morbidity. Studies of hospital events have the advantage of readily available data for extraction, but early events may be characterized incompletely. After repair of many congenital and acquired heart diseases, early risk of surgery extends well beyond the hospital stay. This has led to reflection on the effect of time frame on studies of clinical experiences. Use of intermediate-term data is likely to characterize the early events well, but requires cross-sectional patient follow-up. Long-term follow-up is essential to establish appropriateness of therapy, but it is expensive and runs the risk of being criticized as being of historical interest only.
Yet another reason for interest in clinical information is to use it for profit or corporate advantage. At present, the philosophies of scientific investigation and business are irreconcilable. One thrives on open dissemination of information, the other on proprietary information offering a competitive advantage. In an era of dwindling public resources for research and increasing commercial funding, we may be seeing the beginning of the end of open scientific inquiry.
Is there, then, a future for quantitative analysis of the results of therapy, as there was in the developmental phase of cardiac surgery? Kirklin and Barratt-Boyes wrote in their preface to the second edition of this book:
The second edition reflects data and outcomes from an era of largely unregulated medical care, and similar data may be impossible to gather and freely analyze when care is largely regulated. This is not intended as an opinion as to the advantages or disadvantages of regulation of health care; indeed, as regulation proceeds, the data in this book, along with other data, should be helpful in establishing priorities and guidelines.
As already noted in both the first and second editions, the last section of each chapter is on indications for operation. In the future, regulations of policymakers may need to be added to the other variables determining indications.
On the horizon is the promise that medicine will become decreasingly empirical and more deterministic. However, as long as treatment of heart disease requires complex procedures, and as long as most are palliative in the life history of chronic disease, there will be a need to understand more fully the nature of the disease, its treatment, and its optimal management. This will require adoption of approaches to data that are inescapably philosophical.
In response to the American Medical Association's Resolution 309 (I-98), a Clinical Research Summit and subsequently an ongoing Clinical Research Roundtable (IOM) have sought to define and reenergize clinical research. The most important aspects of the definition of clinical research are that (1) it is but one component of medical and health research aimed at producing new knowledge; (2) the knowledge produced should be valuable for understanding the nature of disease, its treatment, and prevention; and (3) it embraces a wide spectrum of types of research. Here we highlight only two broad examples of that spectrum: clinical trials with randomly assigned treatment and clinical studies with nonrandomly assigned treatment —both of which are interrelated with clinical effectiveness research. 2
2 In the United States, the Federal Council for Comparative Effectiveness Research has defined this type of research as “The conduct and synthesis of research comparing the benefits and harms of different interventions and strategies to prevent, diagnose, treat and monitor health conditions in ‘real world’ settings.” The purpose of this research is to improve health outcomes by developing and disseminating evidence-based information to patients, clinicians, and other decision makers, responding to their expressed needs about which interventions are most effective for which patients under specific circumstances.
Controlled trials date back at least to biblical times when casting of lots was used as a fair mechanism for decision making under uncertainty (Numbers 33 : 54). Solomon noted, “The lot causeth disputes to cease, and it decideth between the mighty” (Proverbs 18 : 18). An early clinical trial took place in the Court of Nebuchadnezzar, king of Babylon (modern Iraq). He ordered several gifted Hebrew youths (“well favored, skillful in all wisdom, cunning in knowledge, and understanding science”) to reside at his palace for 3 years as if they were his own children. He proposed to train them in Chaldean knowledge and language. Among them were Daniel and the familiar Shadrach, Meshach, and Abednego. Daniel objected to the Babylonian diet, and so proposed a 10-day clinical trial: The Hebrews would be fed a vegetarian diet with water, while the children of the king would be fed the king's meat and wine. After 10 days, the condition of the Hebrews was determined to be better than that of the king's children, and they received permission to continue to eat their own diet (Daniel 1:1-15). (This is remarkably reminiscent of the contemporary controversy surrounding carbohydrate-rich vs. protein-rich diets.)
The first modern placebo-controlled, double-blinded, randomized clinical trial was carried out in England by Sir Austin Bradford Hill on the effectiveness of streptomycin vs. bed rest alone for treatment of tuberculosis, although 17th- and 18th-century unblinded trials have been cited as historical predecessors.
Clinical trials in which cardiac surgical procedures and medical therapy have been randomly assigned have made major contributions to our knowledge of treatment and outcomes of heart disease. Notable examples are the Veterans Administration (VA) study of CABG, the Coronary Artery Surgery Study (CASS) trial of CABG, the European Coronary Surgery Study trials, and the PARTNER trial of percutaneous aortic valve replacement. Trials of CABG vs. percutaneous coronary intervention have also been important (e.g., the Balloon Angioplasty Revascularization Investigation [BARI]).
Randomization of treatment assignment has three valuable and unique characteristics:
It eliminates selection factors (bias) in treatment assignment (although this can be defeated at least partially by enrollment bias).
It distributes patient characteristics equally between groups, whether they are measured or not, known or unknown (balance), a well-accepted method of risk adjustment.
It meets assumptions of statistical tests used to compare end points.
Randomized clinical trials are also characterized by concurrent treatment, excellent and complete compilation of data gathered according to explicit definitions, and proper follow-up evaluation of patients. These operational byproducts may have contributed nearly as much new knowledge as the random assignment of treatment.
Unfortunately, it has become ritualistic for some to dismiss out of hand all information, inferences, and comparisons relating to outcome events derived from experiences in which treatment was not randomly assigned. If this attitude is valid, then much of the information now used to manage patients with cardiac disease would have to be dismissed and ignored! Investigations concerning differences of outcome among different physicians, different institutions, and different time periods would have to be abandoned. However, moral justification may not be present for a randomized comparison of procedures and protocols that clinical experience strongly suggests have an important difference. (The difficulty of recruitment in BARI reflects this problem.) In fact, when Benson and Hartz investigated differences between randomized trials and observational comparisons over a broad range of medical and surgical interventions, they found “little evidence that estimates of treatment effects in observational studies reported after 1984 are consistently larger than or qualitatively different from those obtained in randomized controlled studies.” (See, however, the rebuttal by Pocock and Elbourne. ) These findings were confirmed by Concato and colleagues. Nevertheless, we acknowledge a hierarchy of clinical research study designs, and the randomized trial generates the most secure information about treatment differences.
Trials in which treatment is randomly assigned are testing a hypothesis, and hypothesis testing in general requires a yes or no answer unperturbed by uncontrollable factors. Thus ideally, the study is of short duration, with all participants blinded and a treatment that can be well standardized. However, in many clinical situations involving patients with congenital or acquired heart disease, the time-relatedness of freedom from an unfavorable outcome event is important and can jeopardize interpretation of the trial. This is because individual patients assign different values to different durations of time-related freedoms, in part because differing severities of disease (and corresponding differences in natural history) affect different time frames and in part because the longer the trial, the more likely there will be crossovers (e.g., from medical to surgical therapy). Also, the greater the number of risk factors associated with the condition for which treatment is being evaluated, the greater the potential heterogeneity (number of subsets) of patients with that condition and the greater the likelihood that a yes/no answer will apply only to some subset of patients. In such situations, a randomized trial may have the disadvantage of including only a limited number of subsets. It may in fact apply to no subset, because the “average patient” for whom the answer is derived may not exist except as a computation. Trials have addressed this problem by basing the randomization on subsets or by later analyzing subsets by stratification (but see concerns raised by Guillemin ) or by multivariable analysis.
These considerations, in addition to ethical concerns, have fueled the debate about whether surgery is an appropriate arena for randomized trials of innovation, devices, and operations. Some argue strongly that randomization should be required at the outset of every introduction of new therapy. In three related articles arising from the Balliol Colloquium held at the University of Oxford between 2007 and 2009, clinicians and anesthesiologists sought to clarify the issues surrounding surgical clinical trials. They recognized important stages in developing a surgical technique, starting with innovation, progressing through development and exploration, to assessment and long-term outcomes. They then explore options for evaluative studies and barriers to each, including sham operations and nonoperative treatment alternatives. They end with an IDEAL model for surgical development (idea, development, exploration, assessment, long-term study) and the role of feasibility-randomized-trials in exploration, and definitive trials in assessment, and registries in long-term surveillance.
Steven Piantadosi of Johns Hopkins University describes a number of important methodological problems with conducting successful surgical trials, however (personal communication; November 2001):
Operations are often not amenable to blinding or use of placebos (sham operations), although there is growing acceptance of this in some cases of surgery, in part because of the huge placebo effect of surgery. This can introduce bias that may be impossible to control; however, thoughtful and creative study designs can often produce substantial blinding, such as of those assessing outcome.
Selection bias is difficult to avoid. He notes that it is insufficient to compare patients undergoing operation with those who do not, no matter how similar the groups appear, unless every patient not undergoing operation is completely eligible for surgical intervention. Judgment is a characteristic of a good surgeon, and the better the surgical judgment, the more likely bias will enter any trial of surgical vs. nonsurgical therapy, even if it is the bias of selecting patients for the trial.
Surgical therapy is skill-based. Therefore, any result obtained from a trial consists of the inextricable confounding of (1) procedure efficacy and (2) surgical skill.
Surgery is largely unregulated. Every operation is different, and particularly in treatment of complex congenital heart diseases, tailoring operations to the specific anomaly is expected and often necessary for patient survival. There is little uniformity from patient to patient to provide a basis for randomizing therapy.
Given these potential obstacles to adequate evaluation of surgical procedures ever occurring, McCulloch has proposed a hybrid strategy that begins with a prospective but nonrandomized surgical study during the dissemination phase of development (phase II) that progresses to a phase III randomized clinical trial. During the phase II study, learning curves are determined, a likely treatment effect is identified for sample-size calculation, consensus is built, and quality measures to confirm delivery of intended operations are drawn up. Failure of these preliminary steps is perhaps what has stirred much of the controversy over the STICH trial of the Dor procedure.
Moses and others present the case for a balance between randomized clinical trials and observational clinical studies. However, observational studies are beset with these same problems of selection bias and skill variance; thus, not to be overlooked are the development and rapid introduction of powerful new methods for drawing causal inferences from nonrandomized trials (see “ Causal Inferences ” later in this section).
Clinical studies with nonrandomly assigned treatment produce little knowledge when improperly performed and interpreted. Because this is often the case, many physicians have a strong bias against studies of this type. However, when properly performed and interpreted, and particularly when they are multiinstitutional or externally validated, clinical studies of real-world experience can produce secure knowledge (see Comparative Effectiveness footnote on page 266).
This statement would be considered a hypothesis by some, a fact by others. For those who consider it a hypothesis, the hypothesis could be tested as a separate project in a large randomized trial. Hypothetically, such a trial could have two parts: (1) a trial with randomly assigned treatment and (2) a registry with nonrandomly assigned treatment (a registry usually contains many more patients than a trial). For the test, multivariable analyses would be performed of patients in the registry, with propensity adjustment or matching (see “ Propensity Score ” later in this section). The resulting multivariable equations for various unfavorable events would then be used to predict the now-known outcomes of the patients randomly assigned to the alternative forms of therapy. Predicted outcomes would be compared with observed outcomes (see Residual Risk in Section VI ); if they were the same, the validity of the technique of properly performed and analyzed studies with nonrandomly assigned treatment would, in that instance and clinical setting, be established. If they were not the same, the reason should be investigable.
The fundamental objection to using observational clinical data for comparing treatments is that many uncontrolled variables affect outcome. Thus, attributing outcome differences to just one factor—alternative treatment—stretches credibility. Even a cursory glance at the characteristics of patients treated one way vs. another usually reveals that they are different groups. This should be expected because treatment has been selected by experts who believe they know what is best for a given patient. The accusation that one is comparing apples and oranges is well justified!
Indeed, a consistent message since Graunt is that risk factors for outcomes from analyses of clinical experience (and these include treatment differences) are associations , not causal relations . Multivariable adjustment for differences in outcome is valuable but not guaranteed to be effective in eliminating selection bias as the genesis of a difference in outcome (a form of confounding ).
Over the years, a number of attempts have been made to move “association” toward “causality.” One such method is the case-control study. The method seems logical and straightforward in concept. Patients in one treatment group (cases) are matched with one or more patients in the other treatment group (controls) according to variables such as age, sex, and ventricular function. However, case matching is rarely easy in practice. How closely matched must the pair of patients be in age? How close in ejection fraction? “We don't have anyone to match this patient in both age and ejection fraction!” The more variables that have to be matched, the more difficult it is to find a match in all specified characteristics. Yet matching on only a few variables may not protect well against apples-and-oranges comparisons. Diabolically, selection factor effects (called bias ), which case matching is intended to reduce, may increase bias when unmatched cases are simply eliminated.
During the 1980s, federal support for complex clinical trials in heart disease was abundant. Perhaps as a result, few of us noticed the important advances being made in statistical methods for valid, nonrandomized comparisons. One example was the seminal 1983 Biometrika paper “The Central Role of the Propensity Score in Observational Studies for Causal Effects” by Rosenbaum and Rubin. In the 1990s, as the funding climate changed, interest in methods for making nonrandomized comparisons accelerated. This interest has accelerated in the 2000s and 2010s as comparative effectiveness research has taken on greater importance, and the concept of a Learning Healthcare System has been advocated by the IOM of the National Academies in the United States.
Apples-to-apples nonrandomized comparisons of outcome can be achieved within certain limitations by use of balancing scores , of which the propensity score is the simplest (see “ Propensity Score ” later in this section). Balancing scores are a class of multivariable statistical methods that identify patients with similar chances of receiving one or the other treatment. Perhaps surprisingly, even astonishingly, patients with similar balancing scores are well balanced with respect to at least all patient, disease, and comorbidity characteristics taken into account in forming the balancing score. This balancing of characteristics permits the most reliable nonrandomized comparisons of treatment outcomes available today. Indeed, developers of balancing score methods claim that the difference in outcome between patients who have similar balancing scores but receive different treatments provides an unbiased estimate of the effect attributable to the comparison variable of interest. That is technical jargon for saying that the method can identify the apples from among the mixed fruit of clinical practice variance, transforming an apples-to-oranges outcomes comparison into an apples-to-apples comparison.
Randomly assigning patients to alternative treatments in clinical trials balances both patient characteristics (at least in the long run) and number of subjects in each treatment arm. In a nonrandomized setting, neither patient characteristics nor number of patients is balanced for each treatment. A balancing score achieves local balance in patient characteristics at the expense of unbalancing n. Tables 6-3 and 6-4 illustrate local balance of patient characteristics achieved by using a specific balancing score known as the propensity score (see “ Propensity Score ” later in this section for details on how it is derived from patient data). Table 6-3 demonstrates that patients on long-term aspirin therapy have dissimilar characteristics from those not on this therapy. Unadjusted comparison of outcomes in these two groups is invalid—an apples-to-oranges comparison. Therefore, multivariable logistic regression analysis (see “ Logistic Regression Analysis ” in Section IV ) was performed to identify factors predictive of treatment received (long-term aspirin vs. not). The resulting logistic equation was solved for each patient's probability of being on long-term aspirin therapy. This probability is one expression of what is known as a propensity score (in this case, the propensity to be on long-term aspirin therapy). Patients were then sorted according to the balancing (propensity) score and divided into five equal-size groups, called quintiles , from low score to high. Thus, patients in each quintile had similar balancing scores (see Table 6-4 ).
| Patient Characteristic | ASA | No ASA | P |
|---|---|---|---|
| n | 2455 | 4072 | |
| Men (%) | 49 | 56 | .001 |
| Age (mean ± SD, years) | 62 ± 11 | 56 ± 12 | <.0001 |
| Smoker (%) | 10 | 13 | .001 |
| Resting heart rate (beats · min −1 ) | 74 ± 13 | 78 ± 14 | <.0001 |
| Ejection fraction (%) | 50 ± 9 | 53 ± 7 | <.0001 |
a Table shows that patient characteristics differ importantly, making direct comparisons of outcome invalid. As shown in original article, many other patient characteristics differed between the two groups.
| Patient Characteristic | Quintile | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| I | II | III | IV | V | ||||||
| ASA | No ASA | ASA | No ASA | ASA | No ASA | ASA | No ASA | ASA | No ASA | |
| n | 113 | 1092 | 194 | 1111 | 384 | 922 | 719 | 586 | 1045 | 261 |
| Men (%) | 22 | 22 | 57 | 63 | 74 | 71 | 78 | 78 | 88 | 87 |
| Age (years) | 55 | 49 | 56 | 55 | 61 | 61 | 62 | 64 | 63 | 65 |
| Smoker (%) | 15 | 13 | 15 | 15 | 12 | 11 | 11 | 13 | 7 | 9 |
| Resting heart rate (beats • min −1 ) | 84 | 83 | 79 | 79 | 76 | 76 | 76 | 76 | 71 | 73 |
| Ejection fraction (%) | 53 | 54 | 54 | 54 | 53 | 53 | 49 | 49 | 49 | 48 |
a Table illustrates that balancing patient characteristics by the propensity score comes at the expense of unbalancing number of patients within comparable quintiles.
Simply by virtue of having similar balancing scores, patients within each quintile were found to have similar characteristics (except for age in quintile I). As might be expected, patient characteristics differed importantly from one quintile to the next. For example, most patients in quintile I were women; most in quintile V were men. Except for unbalanced n , these quintiles look like five individual randomized trials with differing entry and exclusion criteria, which is exactly what balancing scores are intended to achieve! Thus, the propensity score balanced essentially all patient characteristics within localized subsets of patients, in contrast to randomized clinical trials that balance both patient characteristics and n globally within the trial.
To achieve this balance, a widely dissimilar number of patients actually received long-term aspirin therapy from quintile to quintile. Quintile I contained only a few patients who received long-term aspirin therapy, whereas quintile V had few not receiving aspirin. Thus, balance in patient characteristics was achieved by unbalancing n. Table 6-5 illustrates this unbalancing of n to achieve balanced patient characteristics in not only the long-term aspirin use study but also a study of atrial fibrillation in which nature is the selecting mechanism, and on- vs. off-pump CABG.
| Study | Factor Present, n | Factor Absent, n |
|---|---|---|
| Long-Term Aspirin Use | ||
| Quintile 1 | 113 | 1192 |
| Quintile 2 | 194 | 1111 |
| Quintile 3 | 384 | 922 |
| Quintile 4 | 719 | 586 |
| Quintile 5 | 1045 | 261 |
| Natural Selection: Preoperative AF in Degenerative MV Disease | ||
| Quintile 1 | 2 | 225 |
| Quintile 2 | 13 | 214 |
| Quintile 3 | 32 | 195 |
| Quintile 4 | 78 | 149 |
| Quintile 5 | 162 | 66 |
| OPCAB versus On-Pump | ||
| Quintile 1 | 40 | 702 |
| Quintile 2 | 71 | 671 |
| Quintile 3 | 61 | 682 |
| Quintile 4 | 90 | 652 |
| Quintile 5 | 219 | 524 |
The most widely used balancing score is the propensity score. It provides for each patient an estimate of the propensity toward (probability of) belonging to one group vs. another (group membership) . Here we describe (1) designing the nonrandomized study, (2) constructing a propensity model, (3) calculating a propensity score for each patient using the propensity model, and (4) using the propensity score in various ways for effecting a balanced comparison.
The essential approach to a comparison of treatment outcomes in a nonrandomized setting is to design the comparison as if it were a randomized clinical trial and to interpret the resulting analyses as if they emanated from such a trial. This essential approach is emphasized in Rubin's 2007 article, “The Design versus the Analysis of Observational Studies for Causal Effects: Parallels with the Design of Randomized Trials.”
As noted by Rubin, “I mean all contemplating, collecting, organizing, and analyzing data that takes place prior to seeing any outcome data.” He emphasizes by this statement his thesis that a nonrandomized set of observations should be conceptualized as a broken randomized experiment…with a lost rule for “patient allocation, and specifically for the propensity score, which the analysis will attempt to construct.” For example, the investigator should ask, “Could each patient in all comparison groups be treated by all therapies considered? If not, this constitutes specific inclusion and exclusion criteria. If this were a randomized trial, when would randomization take place? One must only use variables to construct a propensity score that would be known at the time randomization would have occurred, not after that; this means that variables chosen in the propensity score analysis are not those that could possibly be affected by the treatment.
For a two-group comparison, typically, multivariable logistic regression is used to identify factors predictive of group membership (see “ Logistic Regression Analysis ” in Section IV ). In most respects, this is what cardiac surgery groups have done for years—find correlates of an event. In this case, it is not risk factors for an outcome event, but rather correlates of membership in one or the other comparison group of interest.
We recommend initially formulating a parsimonious multivariable explanatory model that identifies common denominators of group membership (see Multivariable Analysis in Section IV ). Once this traditional modeling is completed, a further step is taken to generate the propensity model , which augments the traditional model by other factors, even if not statistically significant. Thus, the propensity model is not parsimonious. The goal is to balance patient characteristics by whatever means possible, incorporating “everything” recorded that may relate to either systematic bias or simply bad luck, no matter the statistical significance. (However, this is not to say that the addition of nonsignificant variables is done carelessly; the same rigor in variable preparation described in Multivariable Analysis in Section IV is mandatory.) It is important to use as many continuous variables as possible to represent these patient characteristics, because it produces a fine, as opposed to coarse, set of values when the propensity score is calculated.
When taken to the extreme, forming the propensity model can cause problems because medical data tend to have many variables that measure the same thing. The solution is to pick one variable from among a closely correlated cluster of variables as a representative of the cluster. An example is to select one variable representing body size from among height, weight, body surface area, and body mass index.
Once the propensity modeling is completed, a propensity score is calculated for each patient. A logistic regression analysis, such as is used for the propensity model, produces a coefficient or numeric weight for each variable ( Box 6-5 ). The coefficient maps the units of measurement of the variable into units of risk. Specifically, a given patient's value for a variable is transformed into risk units by multiplying it by the coefficient. If the coefficient is 1.13 and the variable is “male” with a value of 1 (for “yes”), the result will be 1.13 risk units. If the coefficient is 0.023 for the variable “age” and a patient is 61.3 years old, 0.023 times 61.3 is 1.41 risk units.
Sir Francis Galton, cousin of Charles Darwin, explored the relation between heights of adult children and average height of both parents (midparent height). He found that children born to tall parents were in general shorter than their parents, and children born to short parents, taller. He called this “regression towards mediocrity.” He even generated a “forecaster” for predicting son and daughter height as a function of father and mother height. It is presented in an interesting way as pendulums of a clock, with chains around two different-sized wheels equivalent to the different weights (regression coefficients) generated by the regression equation!
Today, any empirical relation of an outcome or dependent variable to one or more independent variables (see later Box 6-18 ) is termed a regression analysis . Several of these are described below.
The form of a linear regression equation for a single dependent variable Y and a single independent variable x is:
where a is called the intercept (the estimate of Y when x is zero), and b is the slope (the increment in Y for a one-unit change in x ). More generally, when there are a number of x 's:
where β 0 is the intercept, x 1 through x k are independent variables, and β 1 through β k are weights, regression coefficients, or model parameters (see later Box 6-13 ) that are multiplied by each x to produce an incremental change in Y.
It would be surprising if biological systems behaved as a series of additive weighted terms like this. However, this empirical formulation has been valuable under many circumstances in which there has been no basis for constructing a biomathematical model based on biological mechanisms (computational biology).
An important assumption is that Y is distributed in Gaussian fashion (see Box 6-15 ), and this may require the scale of the raw data to be mathematically transformed.
A log-linear regression equation has the following form:
where Ln is the logarithm to base e . Such a format is used, for example, in the Cox proportional hazards regression model (see Section IV ). However, in studies of events (see “ Logistic Regression Analysis ” and Time-Related Events in Section IV ), the estimation procedure does not actually use a Y . Rather, just as in finding the parameter estimates called mean and standard deviation of the Gaussian equation (see Box 6-15 ), parameter estimation procedures use the data directly. Once these parameters are estimated, a predicted Y can be calculated.
A logit-linear regression equation, representing a mathematical transformation of the logistic equation (see Fig. 6-1, A and Section IV ), has the following form:
where Ln is the logarithm to base e and P is probability. The logit-linear equation is applicable to computing probabilities once the β s are estimated.
A model is a representation of a real system, concept, or data, and particularly the functional relationships within these; it is simpler to work with, yet predicts real system, concept, or data behavior.
A mathematical model consists of one or more interrelated equations that represent a real system, concept, or data by mathematical symbols. These equations contain symbols that represent parameters (constants) whose values are estimated from data and an estimating procedure.
A mathematical model may be based on a theory of nature or mechanistic understanding of what the real system, concept, or data represent (biomathematical models or computational biology). It may also be empirical. The latter characterizes most models in statistics, as depicted previously. The Gaussian distribution is an empirical mathematical model of data whose two parameters are called mean and standard deviation (see Box 6-15 ). All mathematical models are more compact than raw data, summarizing them by a small number of parameters in a ratio of 5 to 10 or more to 1.
When applied to mathematical models, it is an equation that can be solved directly with respect to any of its parameter values by simple mathematical manipulation. A linear regression equation is a linear model.
When applied to mathematical models, a nonlinear equation is an equation that cannot be solved directly with respect to its parameter values, but rather must be solved by a sequence of guesses following a recipe (algorithm) that converges on the answer (iterative). The logistic equation is a nonlinear model.
One continues through the list of model variables, multiplying the coefficient by the specific value for each variable. When finished, the resulting products are summed. To this sum is added the intercept of the model (see Box 6-5 ), and the result is the propensity score. Note that technically, the intercept of the model, which is constant for all patients, does not have to be added; however, in addition to using the propensity score in logit risk units as described here, it may be used as a probability, for which the intercept is necessary.
Once the propensity model is constructed and a propensity score is calculated for each patient, three common types of comparison are employed: matching, stratification, and multivariable adjustment.
The propensity score can be used as the sole criterion for matching pairs of patients ( Table 6-6 ). Although a number of matching strategies have been used by statisticians for many years, new optimal matching algorithms have arisen within computer science and operations research. These have been motivated by the need to optimally match volume of Intranet and Internet traffic to computer network configurations. In addition, Rubin (personal communication, 2008) has suggested matching with replacement vs. the usual “greedy” matching, which removes matched patients from further consideration. Indeed, matching can be bootstrapped, creating multiple matched comparison groups over which outcome can be averaged.
| Patient Characteristic | ASA | No ASA |
|---|---|---|
| n | 1351 | 1351 |
| Men (%) | 49 | 51 |
| Age (years) | 60 | 61 |
| Smoker (%) | 50 | 50 |
| Resting heart rate (beats · min −1 ) | 77 | 76 |
| Ejection fraction (%) | 51 | 51 |
a Table illustrates ability of the propensity score to produce what appears to be a randomized study balancing both patient characteristics and n .
Rarely does one find exact matches. Instead, a patient is selected from the control group whose propensity score is nearest to that of a patient in the case group. If multiple patients are close in propensity scores, optimal selection among these candidates can be used. Remarkably, problems of matching on multiple variables disappear by compressing all patient characteristics into a single score (compare Table 6-6 with unmatched data in Table 6-3 ).
Tables 6-4 and 6-6 demonstrate that such matching works astonishingly well. The comparison data sets have all the appearances of a randomized study! The average effect of the comparison variable of interest is assessed as the difference in outcome between the groups of matched pairs. However, unlike a randomized study, the method is unlikely to balance unmeasured variables well, and this may be fatal to the inference.
Once patients are matched, it is important to diagnostically test the quality of matching. This can be accomplished visually by graphs of standardized differences ( Fig. 6-3 ). Differences that were substantial should virtually disappear. If they do not, it is possible that interaction terms (multiplicative factors rather than additive factors) may be required.

A graph of propensity scores for the groups is instructive ( Fig. 6-4 ). The scores for two treatments may nearly overlap, as they would for a randomized trial. On the other hand, there may be little overlap, as in Fig. 6-5 , and the comparison focuses on the center part of the spectrum of propensity score where there is substantial overlap (virtual equipoise).

 and less invasive (bars below zero line) approaches for aortic valve replacement. Darkened area represents matched patient pairs, showing that they cover the complete spectrum of cases but predominate in the central area (area of “virtual equipoise”).")
Outcome can be compared within broad groupings of patients called strata or subclasses , according to propensity score. After patients are sorted by propensity score, they are divided into equal-sized groups. For example, they may be split into five groups, or quintiles (see Tables 6-4 and 6-5 ), but fewer or more groups may be used, depending on the size of the study. Comparison of outcome for the comparison variable of interest is made within each stratum. If a consistent difference in outcome is not observed across strata, intensive investigation is required. Usually, something is discovered about the characteristics of the disease, the patients, or their clinical condition that results in different outcomes across the spectrum of disease. For example, in their study of ischemic mitral regurgitation, Gillinov and colleagues discovered that the difference in survival between those undergoing repair vs. replacement progressively narrowed as complexity of the pattern of regurgitation increased and condition of the patient worsened ( Fig. 6-6 ). Apparent anomalies such as this give important insight into the nature of the disease and its treatment.
; solid lines enclosed within dashed 68% CLs represent parametric survival estimates; numbers in parentheses are numbers of patients traced beyond that point. P values are for log-rank test. A, Quintile I. B, Quintile II. C, Quintiles III through V.")
The propensity score for each patient can be included in a multivariable analysis of outcome. Such an analysis includes both the comparison variable of interest and the propensity score. The propensity score adjusts the apparent influence of the comparison variable of interest for patient selection differences not accounted for by other variables in the analysis.
Occasionally the propensity score remains statistically significant in such a multivariable model. This constitutes evidence that adjustment for selection factors by multivariable analysis alone is ineffective, something that cannot be ignored. It may mean that not all variables important for bias reduction have been incorporated into the model, such as when one is using a simple set of variables. It may mean that an important modulating or synergistic effect of the comparison variable occurs across propensity scores, as noted previously (e.g., the mechanism of disease may be different within quintiles). It may mean that important interactions of the variable of interest with other variables have not been accounted for, leading to a systematic difference identified by the propensity score. The collaborating statistician must investigate and resolve these possibilities. Understanding aside, this statistically significant propensity score has performed its intended function of adjusting the variable representing the group difference.
In some settings in which the number of events is small, the propensity score can be used as the sole means of adjusting for the variable representing the groups being compared.
The propensity score may reveal that a large number of patients in one group do not have scores close to patients in the other. Thus, some patients may not be matched. If stratification is used, quintiles of patients may have hardly any matches at one or the other, or both, ends of the propensity spectrum, and these remaining may not be well matched.
The knee-jerk reaction is to infer that these unmatched patients represent, indeed, apples and oranges unsuited for direct comparison. However, the most common reason for lack of matches is that a strong surrogate for the comparison group variable has been included inadvertently in the propensity score. This variable must be removed and the propensity model revised. For example, Banbury and colleagues studied blood use with vacuum-assisted venous return (VAVR) by comparing two sequential VAVR configurations with gravity drainage. Because the three groups represented consecutive sequences of patients, date of operation was a strong surrogate for group membership. Furthermore, physical configuration and size of tubing and cannulae varied systematically among groups. Thus, priming volume also was a strong surrogate for group. Neither could be used in forming propensity scores (multiple scores in this instance).
If this is not the case, the analysis may indeed have identified truly unmatchable cases (mixed fruit). In some settings, they represent a different end of the spectrum of disease for which different therapies have been applied systematically. Often the first clue to this “anomaly” is finding that the influence of the comparison variable of interest is inconsistent across quintiles. Indeed, this emphasizes the nature of comparisons with balancing score methodology: the comparisons relate only to the subset of patients who are truly apples-to-apples. Comparing these apples to the remaining oranges with respect to outcomes is not valid. The oranges result from systematic selection of patients for one vs. the other treatment. The area of broad overlap of propensity scores, in contrast, can be thought of as the area of virtual equipoise (see Fig. 6-5 ).
Thus, when apples and oranges (and other “mixed fruit”) are revealed by a propensity analysis, investigation should be intensified rather than the oranges simply being set aside. After the investigations are complete, comparisons among the well-matched patients can proceed with known boundaries within which valid comparisons are possible.
Some investigators tell us that balancing score methods are valid only for large studies, citing Rubin. It is true that large numbers facilitate certain uses of these scores, such as stratification. Case-control matching is also better when a large group of controls far exceeding cases is available. However, we believe there is considerable latitude in matching that still reduces bias; the method seems to “work” even for modest-sized data sets.
Another limitation is having few variables available for propensity modeling. The propensity score is seriously degraded when important variables influencing selection have not been collected. A corollary to this is that unmeasured variables cannot be reliably balanced. If these are influential on outcome, a spurious inference may be made.
The propensity score may not eliminate all selection bias. This may be attributed to limitations of the modeling itself imposed by the linear combination of factors in the regression analysis that generates the balancing score (see Box 6-5 ). If the comparison data sets are comparable in size, it may not be possible to match every patient in the smaller of the two data sets, simply because closely comparable patients have been “used up,” unless bootstrap sampling with replacement has been used.
Perhaps the most important limitation is inextricable confounding. Suppose one wishes to compare on-pump CABG with off-pump operations. One designs a study to compare the results of institution A, which performs only off-pump bypass, with those of institution B, which performs only on-pump bypass. Even after careful application of propensity score methods, it remains impossible to distinguish between an institutional and a treatment difference, because they are inextricably intertwined (confounded); that is, the values for institution and treatment are 100% correlated.
At times, one may wish to compare more than two groups, such as groups representing three different valve types. Under this circumstance, multiple propensity models are formulated. We prefer to generate fully conditional multiple logistic propensity scores (see “ Polytomous and Ordinal Logistic Regression ” in Section IV ), although some believe this “correctness” is not essential.
Most applications of balancing scores have been concerned with dichotomous (yes/no) comparison group variables. However, balancing scores can be extended to a multiple-state ordered variable (ordinal) or even a continuous variable. An example of the latter is use of correlates of prosthesis size as a balancing score to isolate the possible causal influence of valve size on outcome.
Logistic regression is not the only way to formulate propensity scores. A nonparametric machine learning technique—random forests (see Classification Methods in Section VI )—can be used and has been found by Lee and colleagues to better balance groups, with reduced bias. We have formulated a generalized theorem as an extension of the work of Imai and van Dyk for propensity scores and devised a data-adaptive, random-forest nearest-neighbor algorithm that simultaneously matches patients and estimates the treatment effect from thousands of bootstrap samples, while simultaneously refining the characteristics of “true” oranges—noncomparable patients.
Marbán and Braunwald, in reflecting on training the clinician-investigator, provide guiding principles for successful clinical research. Among these:
Choose the right project.
Embrace the unknown.
Use state-of-the-art approaches.
Do not become the slave of a single technique.
Never underestimate the power of the written or spoken word.
In this subsection, we emphasize these principles and suggest ways to operationalize them.
Because of increasingly limited resources for conducting serious clinical research, a deliberate plan is needed to successfully carry a study through from inception to publication. Here we outline such a plan for study of a clinical question for which clinical experience (a patient cohort) will provide the data. 3 This plan appears as a linear workflow ( Fig. 6-7 ); in reality, most research efforts do not proceed linearly but rather iteratively, with each step being more refined and usually more focused right up to the last revision of the manuscript. As is true of most workflow, there are mileposts at which there need to be deliverables , whether a written proposal, data, analyses, tables and graphs, a manuscript, or page proofs.

3 Although the technique described is aimed at clinical studies of cohorts of patients, many aspects apply to randomized clinical trials, retrospective clinical studies, and even laboratory research.
Because of the necessity for Institutional Review Board (Ethics Committee) oversight, but also because it is good science, every serious clinical study needs a formal proposal ( Box 6-6 ). This proposal serves to clarify and bring into focus the question being asked. A common mistake is to ask questions that are unfocused, or uninteresting, or overworked, or that do not target an area of importance. Marbán and Braunwald say, “Ask a bold question…about which you can feel passionate.” Brainstorming with fellow surgeons and collaborators is essential. The first deliverable is the research question, well debated.
The title of a research proposal should reflect the question (topic) being addressed.
Name the principal and collaborators. Just performing surgery should not confer investigator (or author) status. Often overlooked is inclusion of a collaborating scientist in quantitative sciences (e.g., biostatistics) from the outset of the study and investigators from other medical disciplines. This is an error that has increasing ramifications as the study progresses.
Report what is unknown or what is controversial or the current state of knowledge to indicate why a study is needed. “Background” answers the question “So what?” Some advocate writing a formal review paper; others advocate identifying truly key papers only.
Clearly state the purpose (aim) of the study. Often this is best stated as a question. The statement must be well formulated and focused; it is the single most important ingredient for success. It should be revisited, revised, restated, and kept uppermost in mind throughout the study and its eventual presentation. The study cannot be initiated without this step; the study group, end points, variables, and analyses all depend on it.
What is the appropriate study group pertinent to answering the research question? Define both inclusion and exclusion criteria and well-justified inclusive dates. If one proposes that outcome is improved or different, a comparison group is needed. If one proposes to study an event , this is a numerator; both numerator and denominator are needed.
End points are the study outcomes. Each must relate and contribute to answering the research question. State them specifically—their exact, reproducible, and unequivocal definitions—determine how they can be assessed in each individual in the study, and show how each relates to the study. One temptation is to specify many end points that are unrelated to the research question and spend too little time thinking about what end points are critical.
What variables can be obtained from electronic sources? Some aspects of these data may need to be verified. Of vital importance is determining the units of measurement for values from electronic sources. For example, in one source, height may be in inches and in another in centimeters!
For many studies, at least some values for variables needed are not available electronically. This requires developing a database for their acquisition. Note that for successful data analysis, the vocabulary for these variables must be controlled, meaning that all possible values (including “unknown”) for each variable must be explicitly specified at the outset (no “free text”). These will become “pick lists” for data entry.
Importantly, specify only those study-specific variables needed to answer the research question. The natural tendency is to collect data for too many variables, with little thought given to how they might be used. This wastes scarce resources and compromises the quality of collecting relevant variables. Dr. John Kirklin called this “the Christmas tree effect.”
For any study, a minimum sample size is needed to detect an effect reliably. For events (e.g., death), sample size is dependent on the number of events, not size of the study group (see Box 6-4 ).
Successful projects are built on ascertaining that (1) the study population can be identified reliably (ideally from electronic databases), (2) the values for variables required are either already in electronic format (but may need to be verified) or can be obtained readily by review of medical documents, (3) the sample size is sufficient to answer the question (see Box 6-4 ), (4) clinical practice is not completely confounded with the question being asked (one cannot compare two techniques if only one is performed; one may not be able to unravel confounding of two techniques if one surgeon performs one and another the other), and (5) institutional resources are available (one cannot assess PET scans if they are not performed). If the project is not feasible, the study should be abandoned or a long-range plan devised for prospectively obtaining and recording the needed data.
Every study has limitations and anticipated problems. These can be identified by a brief but serious investigation of the state of all the above. If any appear insurmountable or present fatal flaws that preclude later publication, the study should be abandoned. There are always more questions than can be addressed in cardiac surgery, so not being able to answer some specific research question is not an excuse to abandon the search for new knowledge!
Details of analytic methodology should be formulated in collaboration with a statistician or other quantitative analyst (see Section IV ). The surgeon-investigator often does not recognize or know the most appropriate analytic methodology. Collaboration with a statistician or other quantitative professional should reveal appropriate methodology and whether the proposed manner in which data are to be collected will meet the requirements of the methodology. Unfortunately, the surgical literature is not a good resource for determining appropriate methods.
Any proposal that does not use existing data already approved for use in research by an IRB requires study-specific IRB approval before any research is commenced.
Develop a timetable for data abstraction, data set generation (see Fig. 6-7 ), data analysis, and reporting, all deliverables at various mileposts in the study. If the timetable is beyond that tolerable, abandon the study. It is rare for a study to be completed in a year from start to finish. This emphasizes both the bottlenecks of research and the need for lifelong commitment. Although abstract deadlines often drive the timetable, this is a poor milepost (see “Presentation” in Section V ).
The next step is to define clearly the inclusion and exclusion criteria for the study group (see “ Identify Study Group ” in Section III ). A common mistake is to define this group too narrowly, such that cases “fall through the cracks” or an insufficient spectrum is stipulated (see “ Continuity versus Discontinuity in Nature ” earlier in this section). The inclusive dates should be considered carefully. Readers will be suspicious if the dates are “strange”; did you stop just before a series of deaths? Whole years or at least half years dispel these suspicions. Similarly, suspicion arises when a study consists of a “nice” number of patients, such as “the first 100 or 1000 repairs.”
In defining the study group, particular care should be taken to include the denominator. For example, a study may be made of postoperative neurologic events, but it is also important to have a denominator to put these events into context. Or one may study a new surgical technique but be unable to compare it with the standard technique without a comparison group. A study of only numerators is the true definition of a retrospective study; if the denominator is included, it is a prospective or cohort study ( Box 6-7 ).
When clinical data are used for research, some term this retrospective research (e.g., the National Institutes of Health). Epidemiologists also perform what they call retrospective studies that bear no resemblance to typical clinical studies. Thus, confusion has been introduced by use of both the word retrospective and prospective to designate interchangeably two antithetical types of clinical study. The confusion is perpetuated by institutional review boards and government agencies that believe one (prospective), but not the other (retrospective), constitutes “research” on human subjects. The confusion can be eliminated by differentiating between (1) the temporal direction of study design and (2) the temporal direction of data collection for a study, as did Feinstein.
The temporal pursuit of patients may be forward. That is, a cohort (group) of patients is defined at some common time zero, such as operation, and this group is followed for outcomes. Some call this a cohort study. It is the most typical type of study in cardiac surgery: A group of patients is operated on and outcome is assessed. Statisticians have called this a prospective clinical study design ; it moves from a defined time zero forward (which is what the word prospective means).
In contrast, temporal pursuit of patients may be backward. Generally in such a study, an outcome event occurs, such as death from a communicable disease. Starting from this event (generally, a group of such events), the study proceeds backward to attempt to ascertain its cause. Feinstein suggests calling such a study a “trohoc” study ( cohort spelled backwards). For years, many epidemiologists called this a retrospective clinical study design because of its backward temporal direction of study.
Increasingly, retrospective is used to designate the temporal aspect of collecting data from existing clinical records for either a cohort or trohoc study. If charts or radiographs of past patients in a cohort study must be reviewed or echocardiographic features measured, the data collection is retrospective. Feinstein has coined the term “retrolective” for this to avoid use of the word retrospective because of the previously well-understood meaning of the latter in study design. If registry data are collected concurrently with patient care, this process is surely prospective data collection. Feinstein suggests calling such data collection “prolective” data collection.
End points (results, outcomes) must be clearly defined in a reproducible fashion. Generally, every event should be accompanied by its date of occurrence. A common failing is that repeated end points (e.g., thromboembolism, assessments of functional status) are recorded only the first or most recent time they occur. This should never be done. Techniques to analyze repeated end points are available (see Longitudinal Outcomes in Section IV ).
Careful attention must be paid to the variables that will be studied. They should be pertinent to the study question (purpose, objective, hypothesis). A common failing is to collect values for too many variables such that quality suffers. This error usually arises in a reasonable and understandable way. The surgeon-investigator reasons that because the patient records must be reviewed, a number of other variables may as well be abstracted “while there.” Or realizing the full complexity of the clinical setting, the surgeon-investigator feels compelled to collect information on all possible ramifications of the study, even if it is quite peripheral to the focus of the study. This is termed the “Christmas tree effect,” meaning adding ornament upon ornament until they dominate what once was “just” a fine tree. There needs to be a balance between so sparse a set of variables that little can be done by way of risk factor identification or balancing characteristics of the group, and so rich a set of variables that the study flounders or insufficient care is given to the quality and completeness of relevant variables.
Study feasibility must then be assessed. A common failing is forgetting that if an outcome event is the end point, the effective sample size is the number of events observed (see Box 6-4 ). A study may have 1000 patients, but if only 10 events are observed, one cannot find multiple risk factors for those events.
It is wise at the outset to plan the data analysis . Often, for example, the setup for the analysis data set is specific to the methods of analysis. This has to be known by the data managers (see Appendix 6A).
A necessary step is review of the literature. Sifting through articles is often painful, but it should result in identifying those few key papers that are absolutely pertinent to the study. Unfortunately, the search is too often confined to recent literature, and this may result in “reinventing the wheel.”
For executing the study, some realistic time frame with deliverables should be established with collaborators. A common failing is not providing sufficient time for data verification and other aspects of data management that are the heart of a high-quality study. Actual analysis of data may consume one tenth the time of high-quality data preparation.
The completed formal research proposal becomes the second deliverable of a study. It is likely to be updated throughout the course of a study, and we advocate online tracking of each study, with periodic updates of the protocol as one of the tasks in project management.
The next step for successful research is careful attention to the data themselves (see “ Extract Values for Variables ” in Section III ). If electronically available data are to be used, every variable must be defined both medically and at the database content level (see Section II ). If data are to be collected de novo, an appropriate database must be developed (see Fig. 6-7 ). Every variable must be in a format of one value per variable. These variables must follow a controlled vocabulary for analysis, not free text. The deliverable at this stage is a database ready for data to be collected and entered.
Research on existing databases for which blanket IRB approval has been secured may not require separate approval of each study. However, before any de novo data are gathered from medical records or by patient follow-up, separate IRB approval may be required.
There is generally a core set of variables (core data elements) that should be collected for each patient ( Box 6-8 ). In many cardiac surgical settings, these data elements are stipulated by regulatory agencies (e.g., the state of New York) or surgical societies (e.g., Society of Thoracic Surgeons National Database). They include demographics (note that it is essential to record patients’ date of birth rather than age because age can be calculated from date of birth to any chosen “time zero”), the cardiac procedure and possibly clinical symptoms and status at time of operation, past cardiac medical history (particularly prior cardiac procedures), disease etiology, coexisting cardiac defects, coexisting noncardiac morbidity (e.g., diabetes), laboratory measurements known to be consistently associated with clinical outcomes, findings of diagnostic testing, intraoperative findings, support techniques during operation, and factors related to experience (e.g., date of operation).
Core data elements represent the most granular source information that can be logically combined or mapped in multiple ways to generate answers (values) to specific questions (variables). Schematically, this is shown in the following diagram for six core data elements (CDE) from sources a-f.
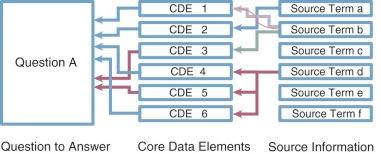
The diagram that follows answers two specific questions concerning use of antianginal medications.
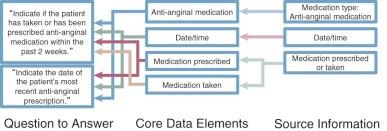
Finally, a third question is asked that relates to a specific medication and requires a combination of temporal reasoning and medication class, prescription, and use.
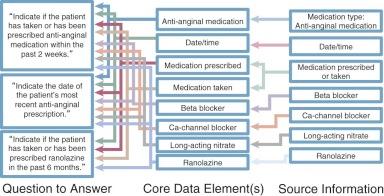
Beyond these core variables, there will likely be a need for variables specific to a particular study. These should be identified and reproducibly defined. The danger is specifying too many variables; however, a thoughtfully compiled list adds depth to a study. Further, experienced investigators realize that in the midst of a study, it occasionally becomes evident that some variables require refinement, others collecting de novo, others rechecking, and others redefining. It is important to understand that when this occurs, the variables must be refined, collected, rechecked, or redefined uniformly for every patient in the study.
Clinical studies are only as accurate and complete as the data available in patients’ records. Therefore, cardiac surgeons and team members seriously interested in scientific progress must ensure their preoperative, operative, and postoperative records are clear, organized, precise, and extensive, so that information gathering from these records can be complete and meaningful. The records should emphasize description, and although they may well contain the conclusions of the moment, it is the description of basic observations that becomes useful in later analyses.
The first step in data verification is to enter values for each data element (variable) for 5 to 10 patients only. These reveal problems of definition, incomplete “pick lists,” missed variables, difficult-to-find variables that may not be worth the effort to locate, poor-quality variables/incomplete recording, lack of good definition, inconsistent recording, and questionable quality of observations. Once these issues are addressed, general data abstraction may proceed (see “ Verify Data ” in Section III ).
When all values for variables are in a computer database, formal verification commences. This can take three general forms: (1) value-by-value checking of recorded data against primary source documents, (2) random quality checking, and (3) automatic reasonableness checking. If a routine activity of recording core data elements (see Section III , Data ) is used, it is wise to verify each element initially to identify those that are rarely in error (these can be “spot checked” by a random process) and those that are more often in error. The latter are usually a small fraction of the whole and are often values requiring interpretation. These may require element-by-element verification.
When it is believed that data are correct (this is an iterative process with the above), they are checked for reasonableness of ranges, including discovery of inconsistencies among correlated values. For example, the database may indicate that a patient had a quadrangular resection of the mitral valve, but someone had failed to record that the posterior leaflet was prolapsing and had ruptured chordae, or the database records that a patient is 60 cm tall and weighs 180 kg; this is likely a problem of confused units of measurement (inches and pounds).
An often underappreciated, unanticipated, and time-consuming effort is conversion of data elements residing in a database to a format suitable for data analysis (see Analysis Data Set in Section III ). Even if the day comes that all medical information is recorded as values for variables in a computer-based patient record (see Section II , Computer-Based Patient Record ), this step will be unavoidable. Statistical procedures require data to be arranged in “columns and rows,” with each column representing values for a single variable (often in numeric format), and each row either a separate patient or multiple records on a single patient (as in repeated-measures longitudinal data analysis). Unfortunately, this conversion process may involve redundancy, such as the necessity to again document all variables and provide a key to the possible values for each.
This process nearly always involves creating additional variables from a single variable, such as a separate variable for each mutually exclusive etiology of cardiomyopathy. These polytomous variables (lists) are then converted to a series of dichotomous variables (best expressed as 0 for absence and 1 for presence of the listed value).
Some categorical variables are ordinal, such as NYHA functional classes. These may have to be reformulated as an ordered number sequence (e.g., 1-4). Variables recorded with units (e.g., weight in kilograms, weight in pounds) must be converted to a common metric.
Calculated variables are also formed. These include body surface area and body mass index from height and weight, z values (see Chapter 1 ) from measured cardiac dimensions, ejection fraction from systolic and diastolic ventricular volumes, intervals between date and time variables for which event indicator variables are created, and many other calculations. Because data conversion, creation of derived variables, and formation of calculated variables is time consuming and error prone, groups that conduct a large number of studies often store trusted, well-verified computer code to perform these operations on a repetitive basis.
Often information is coalesced from multiple databases, and these queries, concatenations, and joining functions transpire in this phase of the process. These otherwise arduous functions can, under some circumstances, be automated. Alternatively, a data warehouse composed of multiple disparate electronic data sources can be implemented and maintained and appears to the investigator as a single data source.
An important activity is managing sporadic missing data. If too many data are missing, the variable may be unsuitable for analysis (see “ Impute Values ” in Section III ). Otherwise, missing value imputation is necessary so that entire patients are not removed from analyses, the default option in many analysis programs.
Specific data analysis methods will be described in Section IV . Here, we simply indicate how this aspect of the research process leads to success.
First, the analysis process leads to understanding of the “raw data,” often called exploratory data analysis. This understanding is gleaned from such analyses as simple descriptive statistics, correlations among variables, simple life tables for time-related events, cumulative distribution graphs of continuously distributed variables (see “ Descriptive Statistics ” in Section III ), and cluster analyses whereby variables with shared information content are identified.
Second, the analytic process attempts to extract meaning from the data by various methods akin to pattern recognition. Answers are sought for questions such as: Which variables relate to outcome and which do not? What inference can be made about whether an association is or is not attributable to chance alone? Might there be a causal relationship? For what might a variable associated with outcome be a surrogate?
What will be discovered is that answering such questions in the most clinically relevant way often outstrips available statistical, biomathematical, and algorithmic methodology! Instead, a question is answered with available techniques, but not the question. Some statisticians, because of insufficient continuing education, lack of needed statistical software, lack of awareness, failure of communication, or lack of time, may explore the data less expertly than required. One of the purposes of this chapter is to stimulate effective collaboration between cardiac surgeons and data analysis experts so that data are analyzed thoroughly and with appropriate methodology.
It is one thing for a statistician to provide a statistical inference; it is quite another for the cardiac surgeon, using that information, to draw meaningful interpretations that affect patient care.
Kirklin and Blackstone empirically found that the most successful way to embark on this interpretive phase of clinical research is to write on a clean sheet of paper the truest two or three sentences that capture the essence of the findings (and no more!). This important exercise produces an ultra-mini abstract for a paper (whether or not it is required by a journal) and provides the roadmap for writing the manuscript (see Scientific Paper in Section V ).
A common error of the surgeon-investigator is to simply summarize the data instead of taking the important step of drawing meaningful clinical inferences from the data and analyses. He or she has not taken the vital step of asking (1) What new knowledge has been gleaned from the clinical investigation? (2) How can this new knowledge be incorporated into better patient care? (3) What do the data suggest in terms of basic research that needs to be stimulated? (4) How can I best communicate information to my local colleagues? (5) How can I best present this information to the cardiac surgical and cardiologic world at large?
Meaningful new knowledge may not be generated because the statistical inferences from data analyses are accepted as the final result. Instead, the results must be studied carefully and many questions asked. Often this will lead to additional analyses that increasingly illuminate the message the data are trying to convey. Graphical depictions are of particular importance in transforming mere numbers on computer printouts to insight. Depictions must lead beyond statistical inference to clinical inference. What have the data revealed about how to better care for patients? This question is the one best linked to the original purpose of the study. If the study has suggested ways to improve patient care, the next step is to put what has been learned into practice (see Section V ).
Most studies generate more new questions than they answer. Some of these new questions require additional clinical research. Others require the surgeon-investigator to stimulate colleagues in the basic sciences to investigate fundamental mechanisms of the disease process.
Because most surgeon-investigators are part of a group, an important facet of generating new knowledge is discussing with colleagues the results, statistical and clinical inferences, and implications of a study. Multiple points of view nearly always clarify rather than obscure their interpretation.
Finally, clinical research is not a proprietary activity. Yet, too often manuscripts fail to eventuate from research. One reason may be that an abstract was not accepted for a meeting, perhaps because the data were not thoroughly digested before its submission. Although abstract deadlines may be important mechanisms for wrapping up studies, they too often stifle a serious and contemplative approach to generating new knowledge. A second reason manuscripts do not get written is that the surgeon-investigator views the task as overwhelming. Possibly he or she has not developed an orderly strategy for writing. We provide some guidance for this in Section V . A third barrier to writing is time demands on the surgeon-investigator. Usually, this results from not making writing a priority in one's professional life. This is a decision that should be made early in one's surgical career. If dissemination of new knowledge is a desire, then writing must be made a high-priority part of one's lifestyle.
Information is a collection of facts. The paper medical record is one such collection of facts about the health care of a patient. In it, observations are recorded (clinical documentation) for communication among healthcare professionals and for workflow (e.g., plan of care, orders). However, perhaps as much as 90% of the information communicated in the care of a patient is never recorded. The attitude of health insurers—“If it is not recorded, it did not happen”—thus represents a sobering lack of appreciation of the way information about patient care is used and communicated. However, it is also an indictment of the way medical practice is documented. Too much is left out of written records, and too many operative reports are poorly organized and incomplete. Too often this reflects the kind of imprecise thinking that gives rise to medical errors (see “ Human Error ” earlier in this section). If important clinical observations are not recorded during patient care, preferably in a clear, complete, and well-organized (structured) fashion, they are unavailable subsequently for clinical research.
In 1991, the IOM (Institute of Medicine) recognized the need not only for computerizing the paper medical record (as the electronic medical record [EMR]) but also for devising a radically different way to record, store, communicate, and use clinical information. They coined the term “computer-based patient record,” or CPR, and distinguished it from the EMR by the fact that it would contain values for variables using a highly controlled vocabulary rather than free text (natural language).
Two decades have passed. Still, there is no universally accepted definition of the CPR beyond that it contains electronically stored information about an individual's lifetime health status and health care. There is no accepted information (data) model, catalog of data elements, or comprehensive controlled medical vocabulary, all of which are fundamental to developing and implementing the envisioned CPR. There is little movement to capture every health encounter in a patient-owned record; rather, data are siloed within institutions.
These issues aside, for the cardiac surgical group interested in serious clinical research, a CPR with a few specific characteristics could enormously facilitate clinical studies. Furthermore, it could transform the results into dynamic, patient-specific, strategic decision-support tools to enhance patient care.
First and foremost, the CPR must consist of values for variables , selected from a controlled vocabulary . This format for recording information is necessary because analysis now and in the foreseeable future must use information that is formatted in a highly structured, precisely defined fashion, not uncontrolled natural language. Extracting structural information from natural language is a formidable challenge and one that should be unnecessary. Second, the CPR must accommodate time as a fundamental attribute. This includes specific time (date:time stamps), inexact time (about 5 years ago), duration (how long an event lasted, including inexact duration), sequence (second myocardial infarction [MI], before, after), and repetition (number of times, such as three MIs). Third, the CPR must store information in a fashion that permits retrieval not only at the individual patient level but also at the group level, according to specified characteristics. Fourth, the CPR will ideally incorporate mechanisms for using results of clinical studies in a patient-specific fashion for decision support in the broadest sense of the term, such as patient management algorithms and patient-specific predictions of outcome from equations developed by research (see “ Use of Incremental Risk Factors ” in Section V ).
There are many other requirements for CPRs, from human-user interfaces, to administrative and financial functions, to healthcare workflow, to human error avoidance systems, that are beyond the scope of the clinical research theme in this section.
If medical information is to be gathered and stored as values for variables, a medical vocabulary and organizing syntax must be available. A technical term for this is ontology.
In Greek philosophy, ontology meant “the nature of things.” Specifically, it meant what actually is (reality), not what is perceived (see “ Human Error ” in Section I ) or known (epistemology). In medicine of the 17th and 18th centuries, however, it came to mean a view of disease as real, distinct, classifiable, definable entities. This idea was adopted by computer science to embrace with a single term everything that formally specifies the concepts and relationships that can exist for some subject, such as medicine. An ontology permits sharing of information, such as a vocabulary of medicine (terms, phrases), variables, definitions of variables, synonyms, all possible values for variables, classification and relationships of variables (e.g., in terms of anatomy, disease, healthcare delivery), semantics, syntax, and other attributes and relationships.
An ontology for all of medicine does not yet exist. Efforts to develop a unified medical language, such as the Unified Medical Language System (UMLS) of the National Library of Medicine, are well underway and becoming increasingly formalized linguistically as ontologies.
Ontology is familiar to clinical researchers, who must always have a controlled vocabulary for values for variables, well-defined variables, and explicit interrelations among variables. Without these, there is no way to accurately interpret analyses or relate results to the findings of other investigators. However, a clinical study is a microscopic view of medicine; scaling up to all of medicine is daunting.
Perhaps, then, the simplest way of thinking about an ontology for the researcher is as dictionaries of variables and values and their organizational structure, and some mechanism to develop and maintain them. These attributes have collectively been called metadata (data about data) or a knowledge base , and metadata-base or knowledge-base management systems , respectively.
An information (data) model is a specification of the arrangement of the most granular piece of information according to specific relationships and the organization of all of these into sets of related information. The objective of an information model is to decrease entropy—that is, to decrease the degree of disorder in the information and thereby increase efficiency of information storage and retrieval (performance).
In 1993 at UAB, John Kirklin led a team effort to develop a CPR that would be ideal for clinical care as well as clinical research. The first step was an attempt to develop an object-oriented information model. These efforts failed. In object technology, only a few formal relationships can be established easily. Failure of the object data model was attributed to the realization that in medicine, “everything is related to everything” on multiple hierarchical (polyhierarchical) levels. Indeed, medical linguistics forms a semantic network.
The most ubiquitous information model in business, the relational database model, was found to be even more unsuitable as a medical information model, just as it is now being found to be unsuitable in complex, rapidly changing, multidimensional businesses such as aircraft building and repair. In relational database technology, variables are arranged as columns of a table, sets of columns are organized as a table, individual patients are in rows, and a set of interrelated tables constitute the database. However, in medicine, information is multidimensional. A given value for a variable must carry with it time, who or what machine generated the value, the context of obtaining the value (“documentation”), format or units of measurement, and a host of attributes and relationships—indeed ontology—that give the value meaning within the context of healthcare delivery. Simply storing a set of values is insufficient. Furthermore, when data must be analyzed, information relevant to the values, such as described earlier, may importantly affect the analysis and must be present even if it seems ancillary. The relational data model also poorly represents and retrieves sequences (in which retention of order is vital) and is difficult to maintain for complex data, because every change (addition, subtraction) in data structure requires the database to be updated.
Popularity of the relational model among clinical researchers stems from its simplicity in handling a microscopic corner of medical information. As soon as a new topic is addressed or new variables must be collected, the typical behavior of the research team is to generate a new specific database. Rarely do these multiple, independent, and to some extent redundant databases communicate with one another across studies. This attests to the inappropriateness of such a simplistic data model for a CPR, and even for a busy cardiac surgery research organization.
A different kind of information model emerged from an important conference at UAB of leaders in the development of several different types of database as part of the CPR project. After review of the strengths and profound limitations of various information models, a novel approach was suggested by Kirklin and then formalized. He proposed that all information that provided context and meaning to a value for a variable be packaged together. He envisioned that such a complex data element should be able to reside as an independent self-sufficient entity. (In computer science terminology, this would be called a completely flattened data model .)
This idea has several meritorious implications. First, an electronic container for a collection of complex data elements could consist of a highly stable, totally generic repository for a CPR because it would be required to possess no knowledge of content of any data element. It could therefore manage important information storage and retrieval functions, implement data encryption for privacy and confidentiality, store knowledge bases used to construct the complex data elements and retrieve them, maintain audit trails, and perform all those functions of database management systems that are independent of data content. The second implication is that as medical knowledge increases, new entries would be made in the knowledge-base dictionaries. These would be updated, not the database structure. Not only would this ease database maintenance, it would enforce documentation in the knowledge base. The third implication, and the one most important for clinical research, is that no a priori limitations would be placed on relations; they could be of any dimensionality considered useful at the time data elements were retrieved for analysis. Thus, the electronic container is a single variable value-pair augmented with contextual documentation and capable of being modified as new or more knowledge accrues.
Essential characteristics of such an information repository are:
Self-documentation at the level of individual values for a variable (complex data element)
Self-reporting at the time of data element retrieval and potential
Self-displaying in a human-computer interface
Self-organizing
The latter is an important attribute for future implementation of what might be called “artificial intelligence” features of a CPR. These may be as simple as self-generation of alerts, solution of multivariable equations for decision support at the individual patient level, or intelligent data mining for undiscovered relations within the information.
About 1995, at the time these ideas were being developed at UAB, similar thinking was going on among computer scientists at Stanford University and the University of Pennsylvania, arising from different stimuli. They termed an information model of complex data elements that carried with them all attributes intended for self-documentation, self-reporting, and self-organizing semistructured data. This phrase meant that the data elements were fully structured, but no necessary relation of one data element to another was presupposed. The culmination of these efforts was a database for storing complex data elements called Lore and a novel query language for retrieving complex data elements called Lorel.
In the 1990s, it was recognized that the information structure suggested by Kirklin and the University of Pennsylvania and Stanford computer scientists could be conceptualized as a directed acyclic graph ( Fig. 6-8 ). At that time, another entity was also rapidly coming into existence with similar properties, but of global proportions: the World Wide Web (WWW, or simply the Web). A Web page is analogous to a complex data element, with an essential feature being that it is self-describing, so it can be retrieved. The Web is the infrastructure for these pages. It has no need to be aware of Web page content. The subject matter has no bounds. Not surprisingly, then, the tools developed for retrieving semistructured data were quickly adapted to what has become known as search engines for the Web. Like Dr. Kirklin's vision of complex data elements, information retrieved by a search engine can become related in ways never envisioned by the person generating it, because full structure is imposed only at the time of retrieval, not at the time of storage.

In 1998, the Lore scientists realized that the information model for semistructured data could be implemented in XML (extensible markup language). XML is a textual language for information representation and exchange, largely developed for document storage and retrieval but adaptable to values for variables.
At least on a conceptual basis, we believe a CPR can be formulated using a semistructured information model that will facilitate clinical research by not imposing restrictions at the time of storage, as relational and object models do.
Subsequently at Cleveland Clinic, investigators have been both harnessing and developing “Semantic Web” tools for data storage and manipulation, in part within the framework of the World Wide Web Consortium (W3C) and in part through ontologies built by Douglas Lenat of Cycorp. W3C is an international community that works with the public to develop Web standards. It is developing a suite of technologies that build on standards associated with the World Wide Web and provide a formal model for representing information in a manner that emphasizes the meaning of terms rather than their structure. It is a vision of how the existing infrastructure of the Web can be extended in such a way that machines can interpret the meaning of data involved in interactions over the Web.
This particular collection of standards is commonly referred to as Semantic Web technologies . They are built on a graph-based data model known as the Resource Description Framework (RDF), as well as a framework for describing conceptual models of RDF data in a particular domain known as the Ontology Web Language (OWL). It also includes a standard querying language called SPARQL .
RDF captures meaning as a collection of triples consisting of components analogous to those of an elementary sentence in natural language: subject, verb, object. Typically, terms in these sentences are resources identified by Uniform Resource Identifiers (URIs). URIs are global identifiers for items of interest (called resources ) in the information space of the Web. Collections of RDF triples constitute an RDF graph.
Many requirements outlined by the IOM as crucial for CPR systems are addressed by using RDF as a data format for patient record content. In particular, our ability to link with other clinical records can be facilitated when RDF is used in this way. Use of URIs as syntax for the names of concepts in RDF graphs is the primary reason for this. The meaning of terms used in a patient record (as well as the patient record itself or some part of it) can be made available over the Web in a (secure) distributed fashion for on-demand retrieval.
A judicious application of Semantic Web technologies can also lead to faster movement of innovation from the research laboratory to the clinic or hospital. In particular, it is envisioned that use of these technologies will improve productivity of research, help raise quality of health care, and enable scientists to formulate new hypotheses, inspiring research based on clinical experience.
The ability to manage that ubiquitous attribute of all medical data— time —is not part of any widely available information retrieval system (generally called query languages ). Some proposals have been tested in a limited fashion, such as the Tzolkin system developed at Stanford University, but the software is not generally available. The reason for needing to consider time is readily apparent. Whenever we think about retrieving medical information along some time axis (e.g., sequence, duration, point in time), new logical relations must be generated to obtain reasonable results. For example, if we ask for all patients younger than 80 years who have undergone a second coronary artery bypass operation followed within 6 months by an MI, a number of time-related logical steps must be formulated. What is meant by patients younger than 80? Younger than 80 when? At the time of initial surgery, second surgery, MI, or at the time of the inquiry? The sequence of coronary artery bypass grafting (CABG) must be ascertained from data elements about each procedure a patient has undergone. Information about the MI and its relation to the date of the second CABG must be retrieved. The process is even more complex if only approximate dates are available.
Perhaps a growing interest pertaining to the time axis in business may stimulate development of better tools for managing queries related to time in medical information.
Data consist of organized information. We add the following further constraints.
First, data consist of values for variables . These values have been selected from a list of all possible values for a variable, and this list is part of a constrained vocabulary. Natural language processing is too primitive at present to allow values to consist of free text, and that will not change in the foreseeable future. Our exploration with linguistics experts of the needed lexical parsing rules to determine from dictated medical notes whether a person experienced a hospital death after cardiac operation produced multiple pages of daunting logic. In part, the complexity arises because of the richness of language that includes euphemisms, synonyms, and misspellings; in part it is because one must also identify negating (“did not expire”), adjudicate probabilities (“may have died”), and examine indirect evidence (no mention of death in available dictated notes, but an autopsy was reported).
Second, data consist of values for variables that have been accurately and precisely defined both at the level of the database and medically. One of the important benefits of multicenter randomized trials, concurrent observational studies, or national registries is that these activities require establishing agreed-upon definitions at the outset. Coupled with this is often intensive and ongoing education of study coordinators and other data-gathering personnel about these definitions, exceptions, and evolution of definitions and standards. There is a mechanism to monitor compliance with these definitions and standards throughout the study, and the same should hold true for any registry. However, a mechanism to ensure similar adherence to definitions is essential even for individual clinical studies. Further, documentation must be in place to identify dates on which changes in definition have occurred, and these must be communicated to the individuals analyzing the data (generally, indicator variables are created that “flag” cases for which definitions of an individual variable have changed). The rigor of establishing good definitions is considered distasteful by investigators who are impatient to collect data, but it is essential for successful research. It is also somewhat of an iterative process, which is why we suggest extracting data on the basis of initial definitions for a few patients scattered over the entire time frame of the study, then refining the definitions. One must also be aware of standards developed by national and international groups of cardiac surgeons and cardiologists assembled for this purpose.
Third, data consist of values for variables that have been organized , generally using a database management system, into a database or data set(s) suitable for analysis. There is an essential translation step in going from even organized information into data in a format compatible with the analytic technique to be employed. For example, if one is analyzing survival after a cardiac surgical procedure, one must define “time zero,” construct the interval from time zero to occurrence of the event of interest from date:time data, generate an indicator variable for whether by the end of follow-up a patient has or has not experienced the event, impute values for additional variables if some of the data are known only inexactly, and manage the problem of possible missing values for some of these variables (see Time-Related Events in Section IV ). These details will not be part of the medical information system but must be created at the time of analysis (see “ Analysis Data Set ” later in this section). This is because at the present time and for the foreseeable future, data analysis procedures presume that data will be organized in a fully structured format, generally a relational one (tables with columns for each variable and rows for each separate observation, which may be a single patient or multiple measurements for a single patient). It is our view that the fully structured organization of data, probably in relational database format (see “ Relational Information Model ” in Section II ), should be imposed only at the point of extraction of values for variables from information (often called the “export” phase in a process termed rectangularization ). This allows the input of data to be semistructured (see “ Semistructured Information Model ” in Section II ), maximally flexible, and with few imposed organizational constraints (outside of retrievability), so that relations among variables are imposed by the research question being asked and not by a priori database constraints.
An idealized, linearized perspective on the process of transforming clinical information to data suitable for analysis requires three broad steps (see Fig. 6-7 ): (1) formulating a clinical research proposal that leads to identifying a suitable study group, (2) gathering proposed variables and values that lead to an electronic data set, and (3) manipulating the values and variables to create a data set in a format suitable for analysis. This is a linear process in theory only. In reality, it contains checks that cause the investigator to retrace steps.
The clinical research proposal (see Box 6-6 ) provides detailed specifications for the study group of interest. The medical specification must be translated into a formal query, generally using a query language that will be used to identify patients in the study group. Query engines include the now-familiar Bing and Google, and the search engines of the National Library of Medicine, including PubMed. For data managers familiar with relational databases, the Structured Query Language (SQL) is a universal query language.
It is frequently true that electronic sources of registry data do not narrow the study group as much as desired. This may require investigating a larger group of candidate patients and selecting by medical records review those who meet the study specifications.
If the semistructured information model is adopted (see “ Semistructured Information Model ” in Section II ) as we advocate, then at the present time, experts in query languages specific to this type of information must be consulted. However, because such information is stored in the same format as Web documents, the increasing sophistication, accuracy, and usability of Internet search engine technology will simplify this process.
The end result of a query is identification of a group of patients (or candidate patients) for the study. The major checks here are whether the patients indeed meet criteria for inclusion and exclusion and whether a sufficient number of patients (or a sufficient number of outcome events, as will be found in subsequent steps; see Box 6-4 ) are retrieved for a meaningful analysis.
A source, or sources, for obtaining values for the set of variables specified in the clinical research proposal must now be identified for the study group (see Fig. 6-4 and Box 6-6 ). Currently these are contained either in some electronic format (e.g., hospital information system) or in the paper record.
Become a Clinical Tree membership for Full access and enjoy Unlimited articles
If you are a member. Log in here